




Python Deep Learning tutorial: Create a GRU (RNN) in TensorFlow
Posted on September 17th, 2018
 Posted by Capri Granville on January 27, 2018 at 7:00pm
Posted by Capri Granville on January 27, 2018 at 7:00pmGuest blog post by Kevin Jacobs.
MLPs (Multi-Layer Perceptrons) are great for many classification and regression tasks. However, it is hard for MLPs to do classification and regression on sequences. In this Python deep learning tutorial, a GRU is implemented in TensorFlow. Tensorflow is one of the many Python Deep Learning libraries.
By the way, another great article on Machine Learning is this article on Machine Learning fraud detection. If you are interested in another article on RNNs, you should definitely read this article on the Elman RNN.
What is a GRU or RNN?
A sequence is an ordered set of items and sequences appear everywhere. In the stock market, the closing price is a sequence. Here, time is the ordering. In sentences, words follow a certain ordering. Therefore, sentences can be viewed as sequences. A gigantic MLP could learn parameters based on sequences, but this would be infeasible in terms of computation time. The family of Recurrent Neural Networks (RNNs) solve this by specifying hidden states which do not only depend on the input, but also on the previous hidden state. GRUs are one of the simplest RNNs. Vanilla RNNs are even simpler, but these models suffer from the Vanishing Gradient problem.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=dFARw8Pm0Gk[/responsive_video]
Mathematical GRU Model
The key idea of GRUs is that the gradient chains do not vanish due to the length of sequences. This is done by allowing the model to pass values completely through the cells. The model is defined as the following [1]:


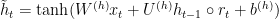

I had a hard time understanding this model, but it turns out that it is not too hard to understand. In the definitions, 
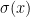
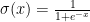
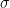

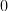
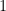

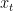
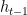
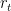
The Task: Adding Numbers
In the code example, a simple task is used for testing the GRU. Given two numbers 

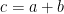
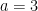

![a = [0, 1, 1]](https://s0.wp.com/latex.php?latex=a+%3D+%5B0%2C+1%2C+1%5D&bg=ffffff&fg=000000&s=0)
![b = [0, 0, 1]](https://s0.wp.com/latex.php?latex=b+%3D+%5B0%2C+0%2C+1%5D&bg=ffffff&fg=000000&s=0)
![a = [1, 1, 0]](https://s0.wp.com/latex.php?latex=a+%3D+%5B1%2C+1%2C+0%5D&bg=ffffff&fg=000000&s=0)
![b = [1, 0, 0]](https://s0.wp.com/latex.php?latex=b+%3D+%5B1%2C+0%2C+0%5D&bg=ffffff&fg=000000&s=0)
![c = [0, 0, 1]](https://s0.wp.com/latex.php?latex=c+%3D+%5B0%2C+0%2C+1%5D&bg=ffffff&fg=000000&s=0)
![[1, 0, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%2C+0%5D&bg=ffffff&fg=000000&s=0)
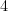
The Code
The code is self-explaining. If you have any questions, feel free to ask! The code can also be found on GitHub. Sharing (or Starring) is Caring :-)!
Results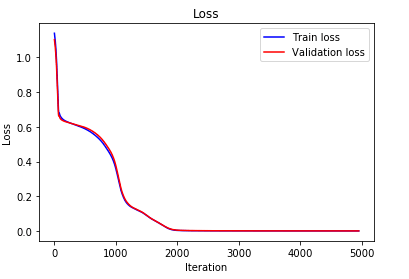
After ~2000 iterations, the model has fully learned how to add 2 integer numbers!
Conclusion (TL;DR)
This Python deep learning tutorial showed how to implement a GRU in Tensorflow. The implementation of the GRU in TensorFlow takes only ~30 lines of code! There are some issues with respect to parallelization, but these issues can be resolved using the TensorFlow API efficiently. In this tutorial, the model is capable of learning how to add two integer numbers (of any length).
To access the source code and view the original article, click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
- Difference between Machine Learning, Data Science, AI, Deep Learnin…
- What is Data Science? 24 Fundamental Articles Answering This Question
- Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Advanced Machine Learning with Basic Excel
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/gru-implementation-in-tensorflow.



