




11 Best Artificial Intelligence Courses, Training & Certifications [2018]
Posted on August 18th, 2018
Our global team of experts have done extensive research to come up with this list of 11 Best Artificial Intelligence Courses, Tutorial, Training and Certifications available online for 2018. These are relevant for beginners, intermediate learners as well as experts. You may also be interested in having a look at Best Data Science Courses.
Contents
- 1. Artificial Intelligence A-Z™: Learn How To Build An AI`
- 2. Artificial Intelligence with Python
- 3. Advanced AI Tutorial: Deep Reinforcement Learning in Python
- 4. Artificial Intelligence Course : Reinforcement Learning in Python
- 5. Machine Learning Certification from University of Washington
- 6. The Beginner’s Guide to Artificial Intelligence in Unity
- 7. Artificial Intelligence (AI) Certification by Columbia University
- 8. Artificial Intelligence Tutorial I: Basics and Games in Java
- 9. Artificial Intelligence Tutorial II – Neural Networks in Java
- 10. Introduction to Artificial Intelligence (AI) Certification by Microsoft
- 11. Essential Mathematics for Artificial Intelligence by Microsoft
1. Artificial Intelligence A-Z™: Learn How To Build An AI
This course that has been attended by close to 50,000 students so far combines the power of Data Science, Machine Learning and Deep Learning to help you create powerful Artificial Intelligence for real applications. Created by Hadelin de Ponteves and Kirill Eremenko, they have taught over 500,000 students between them! You will learn how to build an AI, make a virtual self driving car, make an AI to beat games and also demystify AI models Q-Learning, Deep Q-Learning and Deep Convolutional Q-Learning. All you need to know in order to sign up is High School Mathematics.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=WexeeV0_jL4[/responsive_video]
Key USPs –
– You can learn AI without prior coding experience as well through this program.
– Course comes with 17 hours of on demand online video, 15 articles and 7 supplemental resources.
– The trainers have combined experience of teaching 500,000+ students
– Learn aspects of data science, machine learning and deep learning in one course
Rating : 4.3 out of 5
You can Sign up Here
Review – This is an extraordinary course and is exactly what I was looking for, as the instructors not only give a thorough explanation of deep Q-Learning, their model of the Self-Driving car and how they enjoyed it as it learned had me laughing, and the part of the level of the AI playing Doom was fantastic. – JR Adams
2. Artificial Intelligence with Python
One of the best online instructors of Machine Learning, Data Science and Artificial Intelligence is Frank Kane. In this tutorial, he will teach you about neural networks, artificial intelligence and machine learning techniques. Having worked at Amazon and IMDb, Frank has developed quite a rich experience over time and he is ready to share it all in this program. Through 80 lectures that includes loads of Python code examples, he will teach you how to make predictions using linear regression, polynomial regression, and multivariate regression. He will also help you understand complex multi-level models; build a spam classifier and teach you much more.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=PWExUJ_di2M[/responsive_video]
Key USPs –
– Trainer has taught more than 100,000 students so far
– Trainer comes with strong industry experience
– You will get 12 hours of on demand online lectures with full lifetime access
– Includes sessions on data science, machine learning and deep learning
Rating : 4.5 out of 5
You can Sign up Here
Review : Well paced, progressive and detailed course. It really makes me feel I learned something and can use it. Plus, it provides a few hints that can be re-used in my applications. – Fernand da Fonseca
3. Advanced AI Tutorial: Deep Reinforcement Learning in Python
This is your comprehensive guide to Mastering Artificial Intelligence using Deep Learning and Neural Networks. You will learn how to build various deep learning agents, use advanced reinforcement learning algorithms for a variety of problems, understand Reinforcement Learning with RBF Networks and also use Convolutional Neural Networks with Deep Q-Learning. In order to sign up, it will be idea if you know reinforcement learning basics, MDPs, Dynamic Programming and/or TD Learning.
[responsive_video type=’vimeo’]https://vimeo.com/284576072[/responsive_video]
Key USPs –
– 10,000+ students have taken up this program so far and they look deeply satisfied with the teachings.
– The trainer is much renowned and popular for his teaching methods
– Course updated very regularly to ensure participants get the best knowledge on the subject
Rating : 4.7 out of 5
You can Sign up Here
Review – Well put together and a great learning experience. State of the art techniques and each topic comes with a coding example to show how its used. Definitely a good way to spruce up your deep learning skills. – Freddy Shau
4. Artificial Intelligence Course : Reinforcement Learning in Python
The trainer of this program is a data scientist, big data engineer as well as a full stack software engineer! With a masters in computer engineering and a specialization in machine learning, he is best suited to teach you AI using Python. You will learn to apply gradient-based supervised methods to reinforcement learning, understand the relationship between reinforcement learning and psychology, and understand reinforcement at a technical level. You will need to have experience with few supervised machine learning methods and good object-oriented programming skills in order to attend this course.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=B5Do1C2KRe0[/responsive_video]
Key USPs –
– Regularly updated course so you get the latest information on the subject
– Includes 8 hours of on demand video available online for a lifetime
– Innumerous 5 star ratings from participants
Rating : 4.6 out of 5
Review – “Learnt a great deal about implementing reinforcement learning algorithms, the course introduces reinforcement learning in a very neat and structured manner, which helps a learner easily understand the pros and cons of each approach.” – Bhavesh Parmar
5. Machine Learning Certification from University of Washington
Leading researchers from University of Washington have put together this training. Learn all about Prediction, Classification, Clustering among other key areas. It is created and taught by Emily Fox, Amazon Professor of Machine Learning and Carlos Guestrin, Amazon Professor of Machine Learning. This is an intermediate specialization and you should ideally have preliminary knowledge before signing up.
Key USPs –
– Ideal specialization to level up in your machine learning game
– Course accredited to the University of Washington
– Teachers are both Amazon Professors
– A Certificate offered after the course completion
Rating : 4.6 out of 5
You can Sign up Here
Review – Excellent course, really appreciate the your hard work in creating easy to follow course, very good slides and presenting information and explanations step by step…. oh and also love the on-screen chemistry between both of you and engaging style with students. It has been an enjoyable course. Please keep up the good work.
6. The Beginner’s Guide to Artificial Intelligence in Unity
Dr Penny de Byl, International Award Winning Professor & Best Selling Author
This is for all those who are familiar with C# and the Unity Game Development Engine. Created by Penny de Byl, International Award Winning Professor & Best Selling Author, this training will help you understand how to design and program NPCs with C# in unity. You will get to work with a variety of AI techniques and learn to develop navigation and decision making abilities in NPCs, in addition to implementing AI related Unity Asset plugins into existing projects.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=02onHuJ8bUs[/responsive_video]
Key USPs –
– 8.5 hour course packed with with 10 articles and 45 supplemental resources
– Comprehensive course to grasp the subject
– High ratings from most participants, average rating of 4.7
Rating : 4.7 out of 5
You can Sign up Here
Review – “Great course. I enjoyed every single lesson. I’ve said this before, but I can not understate how utterly VALUABLE it is to have someone with so much teaching experience guiding you through a new subject. This course really opened my eyes to game AI; introducing me to concepts and mechanisms for controlling action in a game that were mysterious “black boxes” to me, until now. This course was fun and I learned many useful things that will serve as a foundation for further learning. The course materials and downloads are a treasure trove of useful scripts and explanations I’m sure I will return to. I’ve enrolled in all Penny de Byl’s courses and look forward the ones that are coming in the future.” – Paul Stringini
7. Artificial Intelligence (AI) Certification by Columbia University
In this specially curated Micro Masters Program, learn the fundamentals of Artificial Intelligence (AI) and get to know how to apply them. Learn to design intelligent agents to solve real-world problems including, search and constraint satisfaction problems. Professor Ansaf Salleb-Aouissi from the Department of Computer Science Columbia University has designed this course and teaches the same. She will teach you about the history of AI, state-space problem representations, uninformed and heuristic search and much more.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=mANw77caYSI[/responsive_video]
Key USPs –
– You will get hands on experience building a basic search agent.
– Divided into 12 weeks, with 8-10 hours to be invested per week.
– The best part is that this is a Free Artifical Intelligence (AI) Course, and you only need to pay for the certification if you wish to obtain the same.
Rating 4.5 out of 5
You can Sign up Here
Review – This is a great course. the content is well designed to arouse curiosity and is challenging. Vocareum is a little challenging. Not able to debug in Vocareum is a serious limitation that causes a learner to be less effecient. I liked the instructor but she could be more engaging. – Pramod Kumar
8. Artificial Intelligence Tutorial I: Basics and Games in Java
Balazs Holczer hails from Budapest, Hungary and he has a masters degree in applied mathematics. In order to attend this course, you should ideally know basic Java or basic math functions. Balazs will teach you help you get a good grasp of artificial intelligence, teach you how AI algorithms work and make you able enough to create AI algorithms on your own from scratch.
Key USPs –
– Learn to demystify meta-heuristics among multiple other AI concepts and terminologies.
– Trainer has an experience of teaching more than 50,000 students online
– Even professionals in their 40s and 50s are benefiting from the course as you can read in the testimonials
Rating : 4.3 out of 5
Review – The lecturer is great. Great in the delivery of the topics and seems pretty knowledgable. Really good presentations and I like the fact that he mentions useful real-life applications of each algorithm and topic. – Marios Paschos
9. Artificial Intelligence Tutorial II – Neural Networks in Java
This is the second course in the series by Balazs, and he will teach you about background of neural networks along with helping you understand how to implement them. This is a 5 hour course with 3 articles and 3 supplemental resources, all available online, for lifetime access.
Rating : 4.4 out of 5
You can Sign up Here
Review – I liked this course. The narrator knows how to keep us interested and he really comprehends his subjects. I had the chance to understand and finally implement a neural network in Java! I would have like to know how to persist the neural network state after the training process and then doing more tests. Maybe it will be cover in another more advanced course. – Sébastien Renaud
10. Introduction to Artificial Intelligence (AI) Certification by Microsoft
This AI certification acts as a high-level overview of AI and teaches how you can leverage cognitive services in your apps. The curriculum has a mix of engaging lectures and real time activities to help you discover the world of AI. You will learn how to process and extract meaning from natural language; and teaching a computer to process AV the way we do. You will also get to know how to build bots to enable interaction between Humans and AI. One key element of the course is that you need to be a user of Microsoft Azure , else you wouldn’t be able to go through all the exercises. So keep that in mind before you sign up for this one. Taught by Graeme Malcolm, who is Senior Content Developer at Microsoft Learning Experiences.
11. Essential Mathematics for Artificial Intelligence by Microsoft
Learn the essential mathematical foundations for machine learning and artificial intelligence from Graeme Malcolm, Senior Content Developer at Microsoft Learning Experiences. Since Machine Learning and AI are essentially built on mathematical principles like Calculus, Linear Algebra, Probability and Statistics, many eager learners find the task of conquering these concepts daunting. To help you build the relevant foundation before you start learning Machine Learning or AI, this course takes you through the useful concepts for the same.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=1wLRcpmAg3c&list=PLZnyIsit9AM5GKDyfClTAbiMPzUEWkJaK&index=2&t=0s[/responsive_video]
Artificial Intelligence is taking over an already smart world. Apps, AR, VR, Machine Learning and so much more is redefining how humans interact with machines. There is immense scope in the field of AI, specially for people who are focused on the future. It can be quite challenging to select and find out which is the best course for you in this domain, and to help you with the same, we have selected and shortlisted the best for you.
So that was our take on what we found to be the Best Artificial Intelligence Courses, Training, Tutorials and Certifications. Hope they helped you find what you were looking for. You may also be interested in reading about Best Machine Learning Online Course , Best Unreal Engine Course, Best Python Tutorial , Best Data Science Course and do search for other courses to find best training programs in other domains. Wish you the best wish learning, growing and earning more! Cheers, Team Digital Defynd 🙂
Content retrieved from: https://digitaldefynd.com/best-artificial-intelligence-courses-training-certifications/.
List Of Free Online Courses On Artificial Intelligence
Posted on August 15th, 2018
3. Stanford University – Machine Learning
4. Columbia University – Machine Learning
5. Nvidia – Fundamentals of Deep Learning for Computer Vision
6. MIT – Deep Learning for Self Driving Cars
8. Deep Reinforcement Learning (UC Berkeley)
9. Machine Learning Crash Course Google
10. Elements of Artificial Intelligence free online course
11. Intro to Artificial Intelligence by Udacity
Content retrieved from: https://www.marktechpost.com/2018/07/07/free-online-courses-on-artificial-intelligence/.
Comparing AI Strategies – Systems of Intelligence
Posted on August 11th, 2018

Posted by William Vorhies on July 24, 2018 at 9:00am
Summary: The fourth and final AI strategy we’ll review is Systems of Intelligence (SOI). This is getting nearly as much attention as the Vertical strategy we previously reviewed. It’s appealing because it seems to offer the financial advantages of a Horizontal strategy but its ability to create a defensible moat requires some fine tuning.
In the last several articles we’ve been looking at different strategies for successful AI companies.
We described Data Dominance, and the Vertical and Horizontal strategies. This brings us to the fourth and last AI strategy, Systems of Intelligence (SOI).
Systems of Intelligence strategy like the Vertical strategy is the brain child of a successful VC, Jerry Chen of Greylock Partners. Like many VCs Mr. Chen is struggling to define criteria for investing in a technology market that is changing so rapidly. So far the Vertical strategy and this Systems of Intelligence strategy are getting the most press. This may or may not indicate agreement from the investing community at large.
The single factor that ties together all four of these strategies however is the need to create a moat of defensibility that will prevent fast followers from simply copying your idea.
Old Moats Have Fallen
It’s interesting to review how the technology market has evolved over time and to remember the moats that were established in each epoch. Gil Dibner a self-described venture investor has offered perhaps the most thoughtful response to SOI, also offers us this brief historical recap of tech VC investing.
- 1970–1985: The “Silicon” Era (e.g. Intel, founded 1968)
- 1975–1990: The “Information” Era (e.g. Microsoft, founded 1975, and Oracle, founded 1977)
- 1985–2000: The “Physical Network” Era (e.g. Cisco, founded 1984)
- 1995–2010: The “Logical Network” Era (e.g. Netscape, founded 1994)
- 2000–2015: The “SaaS” Era (e.g. Salesforce, founded 1999)
- 2005–2020: The “Network Effect” Era (e.g. Facebook, founded 2004 and AirBnB founded 2008)
- 2015–2030: The “System of Intelligence” Era?
If you date the rise of modern ML and AI from the advent of open source NoSQL and Hadoop in 2007 it’s easy to spot that VC investing strategy has been dominated by the Network Effect and the SaaS strategies.
It’s not that these have become invalid. It’s that they have been fully exploited and with very few exceptions the leaders with these strategies have been established, largely freezing out future competitors. On the mind of VCs, startup founders, and all of us interested in AI-first businesses is what comes next? Mr. Chen offers:
“I believe that deep technology moats aren’t completely gone and defensible business models can still be built around IP. If you pick a place in the technology stack and become the absolute best of breed solution you can create a valuable company. However, this means picking a technical problem with few substitutes, that requires hard engineering, and needs operational knowledge to scale.”
What’s the Underlying Concept behind Systems of Intelligence?
In his seminal article on SOI, Chen makes these assertions:
- Today the market favors full stack solutions that frequently relied on the SaaS model. The details of the technology are no longer important as long as the elements of the stack function well together.
- Today’s full-stack is grounded on Systems of Record. There are four fundamental systems of record, one for your customers (CRM), one for your employees (HCM), and two for your assets (ERP financials/ITSM). These are the databases on which your applications are built. The leading players in this SaaS strategy are established and dominant.
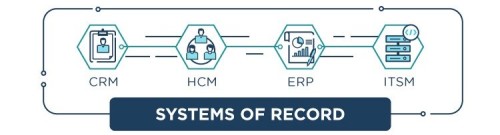
- Systems of Engagement are the interfaces that sit atop the Systems of Record and allow or control how users can utilize and interface with the data. These have migrated up from mainframe terminals, through dashboard visualizers like Tableau, until today we have Slack, Alexa, Wechat, chatbots and every other variant on text and conversational UIs. Older SOE applications tend not to go away but continue to coexist with newer forms.
To gain competitive advantage an SOE must rely on network effect (the friendliness and utility of its interface to attract maximum users) since the data it provides resides in SORs and is shared with other SOEs. The result is today’s modern enterprise stack where SOEs reside atop SORs.

The disruptive core of Systems of Intelligence is that there is emerging a middle layer, the SOI layer that enhances the value of the SORs by adding data from multiple, sometimes external sources, or adding previously unseen insight through the addition of ML/AI.
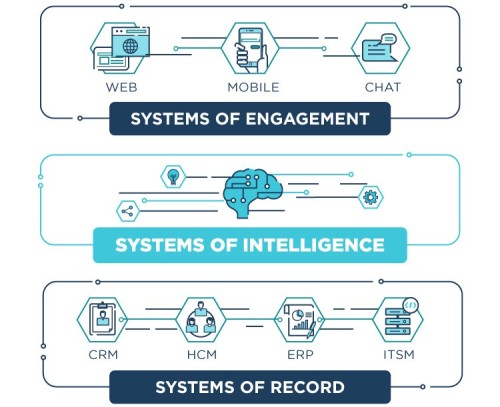
The ability to bridge multiple SORs makes these applications more defensible against the internal capabilities of an SAP or a PeopleSoft, and adding value from external data sources (for example web logs to produce web analytics) makes their moat even wider.
Of course the ability to add value to multiple data sources relies on the value add from ML/AI.
What Do These SOI Opportunities Look Like
First of all it should be evident that this is a horizontal strategy that applies to enterprise platforms. Horizontal strategies are those that represent solutions that can be repurposed across multiple industries.
But unlike the broad horizontal strategy that requires the user/customer to adapt the solution to the specific use case requiring more effort than they are likely to want to apply, the SOI strategy most likely results in a fairly complete standardized application (full stack) around a specific set of processes. The assumption is that these are sufficiently similar across industries that adaptation and configuration can be accomplished through repeatable processes. Chen offers these three potential scenarios:
- Customer facing applications around the customer journey.
- Employee facing applications like HCM.
- ITSM, financials, or infrastructure systems like security, compute/ storage/ networking, and monitoring/ management.
The core capabilities are data blending and ML/AI analysis leading to predictive or even prescriptive actions. You could build these with modern advance analytic platforms like Alteryx, SAS, or SPSS, or simply write them in R or Python.
Of course the focus could be more narrowly a group of target companies across a more specialized industry like finance or construction. Here in addition to requiring process subject matter expertise, industry expertise would also be needed.
Does the Systems of Intelligence Strategy Provide a Defensible Moat?
It’s not clear that it does, at least without adding additional factors to the equation. One of the best discussions and criticisms of SOI comes from Gil Dibner, who self identifies as a venture investor.
The first issue that Dibner identifies is that any fast follower can recreate your product if your only advantage is expertise with ML/AI. Thanks to the open source ethos of ML/AI, none of that IP is truly proprietary.
It may be possible to achieve at least a temporary lead if the technical complexity of your solution is very high, especially in the developing arts of image, text, and speech. However, this advantage is not likely to last. AI is rapidly becoming a commodity.
There are some features that Dibner believes can add some defensibility at least in some cases. One is if the AI technology is extremely hard that we mentioned above.
Another is a variation on the Network Effect. Remember that the idea of network effect says that the value of the network becomes greater as the number of users increases. Generally this is fully exploited and no longer provides a moat.
However, Dibner envisions the possibility of Systems of Network Intelligence. He imagines a system that works across various parties in a supply chain where shared information across customers can be seen to add value.
Another possible moat he offers is the ability to integrate human-in-the-loop applications with the AI so that the resulting hybrid system learns more rapidly and more effectively than the AI alone.
At that point, Dibner starts to suggest features that are clearly from the vertical strategy: domain expertise, data dominance, and full stack applications.
The horizontal cross-industry approach of Systems of Intelligence will no doubt remain its most appealing feature. If defensible, the strength of a single process focused application that could be sold across a variety of industries sound like a pot of gold.
Whether there is any real moat here is questionable.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/comparing-ai-strategies-systems-of-intelligence.
Top Trends in AI in 2018
Posted on August 10th, 2018

Posted by Pradeep Menon on February 19, 2018 at 10:00pm
According to Gartner’s hype cycle of emerging technologies, 2017; Deep Learning and Machine Learning have reached the peak of inflated expectations. Artificial General Intelligence (AGI) and Deep Reinforcement Learning are in the phase of innovation trigger.
We are in 2018. The sentiment over Artificial Intelligence (AI) is euphoric. Every technology firm is jumping on the AI first bandwagon. Companies like Google, Microsoft, Amazon, and Alibaba are pushing the frontiers. There are a plethora of smaller players that are doing cutting-edge work in a niche area. AI is permeating into everyday lives.
As an active practitioner in this field, my views on the top AI trends to look out for in 2018 are as follows:
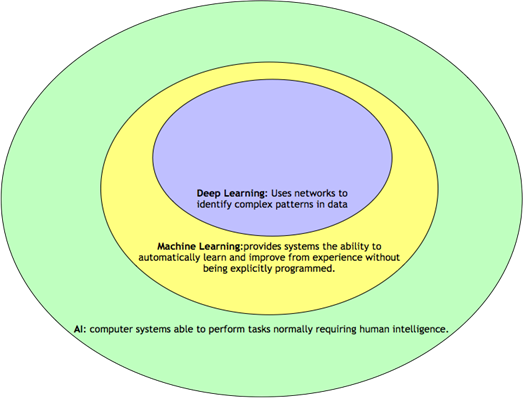
Firstly, let’s get the context of AI correct.
AI encompasses the following:
- Machine Learning (subset of AI)
- Deep Learning (subset of Machine Learning)
Trend #1: Machine Learning to Automated Machine Learning
A typical machine learning process involves the following stages:
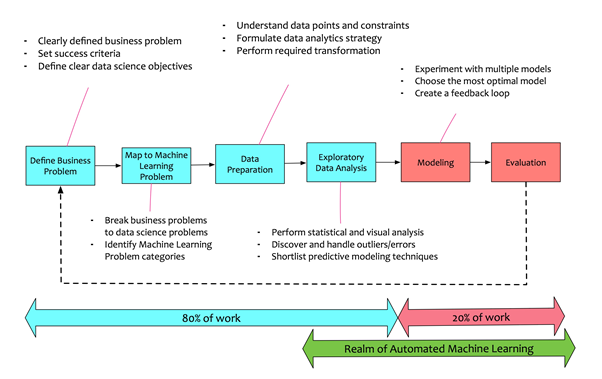
A data scientist spends a lot of time in understanding the data. A data scientist tries to fit multiple models. They try out multiple algorithms to find the best model fitment that provides the optimal result.
Automated machine learning attempts to automate the process of performing exploratory analysis. It tries to automate the process of finding hidden patterns. It automates the training of multiple algorithms. In short, automated machine learning saves a lot of data scientist time. Data scientist spends lesser time in spending on model building and more time on evaluation. Automated machine learning is also a blessing for non-data scientists. It helps them to build decent machine learning models without deep-diving into the mathematics of data science.
In 2018, I see that this trend will become mainstream. Google recently launched AutoML in their cloud computing platform. There are niche companies like Data Robot who specialise in this area and are becoming mainstream.
“Automated Machine Learning will mature in 2018.”Trend #2: Increase in Cloud Adoption for Machine Learning
Machine learning is a lot about data. It is the process of storing data. It is a process of analyzing data, training models and evaluating them. It is a data and compute-intensive process. It is iterative with hits and misses.
Cloud computing provides an ideal platform where machine learning thrives. Cloud computing is not a new concept. Traditional cloud offerings were limited to Infrastructure as a Service (IaaS). Over the past few years, public cloud providers have started offering Machine Learning as a Service. All the big cloud providers have a competitive offering in Machine Learning as a Service.
I see this trend continuing to increase in 2018. The cost of computing and storage in the cloud is lower and on-demand. The costs are controllable. The cloud providers provide out-of-the-box solutions. Data scientist now can spin up analytical sandboxes in the cloud, perform the analysis, experiment with a model and shut it down. They can automate the process as well.Machine learning in the cloud makes the life of a data scientist easier.
“Cloud computing would continue to enable Machine Learning acceleration in 2018.”Trend #3: Deep Learning Becomes Mainstream
Deep learning is a subset of machine learning that utilizes neural network-based algorithms for machine learning tasks. Deep learning methods have proven to be very useful in the field of computer vision, natural language processing, and speech recognition.
Deep learning has been around for some time now. However, deep learning was in relative obscurity all these years. This obscurity was because of the following two reasons:
- The sheer amount of data required to train deep neural networks.
- The sheer computing power required to train deep neural networks.
These reasons cease to exist now. There is data now. There is abundant computing process available. The research in deep learning has never been so ebullient as compared to the past. Increasingly, deep learning is powering the fruition of complex use cases. Deep learning’s application ranges from workplace safety to smart cities to image recognition and online-offline shopping.
This trend will continue in 2018.
“Deep Learning will continue to be rapidly adopted by enterprises in 2018.”Trend #4: AI Regulation Discussion Gains Traction
In 2017, data science community avidly followed the debate between Elon Musk and Mark Zuckerberg. The topic of the debate: Should we fear the rise of AI? Elon Musk had a pessimistic view on the topic. His views: the rise of AI has imminent dangers for humanity. On the other hand, Mark Zuckerberg, had a much more optimistic outlook on the topic. His views: AI would benefit humans.
This debate between these tech tycoons, has everyone thinking about AI and its regulation. In Jan 2018, Microsoft chimed in saying that AI needs to be regulated before it’s too late. There is no easy answer to this question. AI is still an evolving field. Excessive regulations have always stifled innovation. Maintaining a delicate balance is crucial. The regulation of AI is an uncharted territory with technical, legal and even ethical undertones. This is a healthy discussion point.
“Should AI be regulated? This will be a key discussion point in 2018.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/top-trends-in-ai-in-2018.
Comparing AI Strategies – Vertical vs. Horizontal
Posted on August 8th, 2018

Posted by William Vorhies on July 17, 2018 at 7:00am
Summary: Getting an AI startup to scale for an IPO is currently elusive. Several different strategies are being discussed around the industry and here we talk about the horizontal strategy and the increasingly favored vertical strategy.
 Looks like there’s a problem brewing in AI startup land. While AI is most certainly destined to be the next great general purpose technology, on a par with the steam engine, the automobile, and electrification, there just aren’t any examples of new AI-first companies that look like they’ll grow that big.
Looks like there’s a problem brewing in AI startup land. While AI is most certainly destined to be the next great general purpose technology, on a par with the steam engine, the automobile, and electrification, there just aren’t any examples of new AI-first companies that look like they’ll grow that big.
OK, in the 80s it took a long time for the ‘computer age’ to show up in the financial statistics and maybe we’re at the same place. Still, a bunch of people, especially VCs are wondering how to grow an AI company all the way to IPO. This is just now beginning to lead to several different visions of what a successful AI strategy should look like.
Recently we wrote about our own favorite strategy, Data Dominance. There are two or three others you should be aware of and we’ll talk here about two leading strategies, horizontal and vertical.
How Do We Know There’s a Problem?
In 2017 CB Insights reports that of the 120 AI companies that exited the market, 115 did so by acquisition. And the majority of those acquisitions were made by just 9 companies. Guess who.
 AI startups are only a few years old and it’s fair to say that when those founders started out they hoped not only to change the world but to make some life-changing money. That traditionally means IPO.
AI startups are only a few years old and it’s fair to say that when those founders started out they hoped not only to change the world but to make some life-changing money. That traditionally means IPO.
But thanks to the shortage of AI talent, most of these startups ended up being nothing more than acquihires. We hope that at least some made that life-changing money but all those guppies ended up swallowed by whales and are now just features or products, not world changing businesses.
Not all startups will make it. And it certainly requires some soul searching when Google or Amazon come calling. But there’s an open question about whether the strategies of these startups was viable, and that’s where our conversation begins.
Horizontal Strategy
The horizontal strategy is where our industry started, almost by accident. The core concept is to make an AI product or platform that can be used by many industries to solve problems more efficiently than we could before AI.
Then came what VCs refer to as the monoliths: Google, Amazon, IBM, and Microsoft. As we now know, their dominance in their respective areas of data gave them an almost insurmountable lead in offering generalized image, video, speech, and text AI tools using the familiar MLaaS model.
None of these companies started out to be AI-first companies. This grew out of the phenomenon that was once called the data-sidecar strategy. It was there, so why not add it to their offerings.
The monoliths have become so dominant that there’s a widely held principle among VCs that startups should have a maximum distance from these core competencies in order to be defensible.
There’s a second tranche of horizontal competitors below the monoliths including startups. These reach all the way down to some of the newer automated machine learning (AML) companies like OneClick.AI who integrates deep learning with the standard assortment of ML algos.
Horizontal Strategy is Out
The bottom line is that the horizontal strategy is out for a variety of reasons.
- Thanks to the open source ethos of AI there’s really no defensible IP in any ‘proprietary’ DL algorithms that can’t be copied by a fast follower.
- Horizontal companies don’t own the customer’s core problem. They simply provide a tool that must either be adapted by consultants familiar with that industry, or requires the client customer to learn more about DL than they probably wish to.
- They don’t own the training data unique to the customer’s problem so there’s no data defensibility.
- These tools tend to be incrementally better than their traditional MLaaS counterparts, but not break through better. This includes direct competition from the monoliths.
In short, this is not where VCs are putting their money.
Vertical Strategy
The vertical strategy isn’t the only alternative but it’s certainly the most widely talked about these days. It shares the concern over data dominance with that strategy but goes further in specifying other aspects required for success.
The most vocal advocate for vertical is Bradford Cross, a founding partner at Data Collective DCVC, self-described as the world’s leading machine learning and big data venture capital fund. I don’t know if Bradford is the inventor of the vertical strategy but he can certainly claim to have published more in detail than others.
The vertical strategy has four primary principles:
- Full Stack Products: Provide a full-stack fully-integrated solution to the end customer that solves a true ‘hair on fire’ problem. Full stack means from interface to the DL models to the data that drives the models, and all the functionality in between.
- Subject Matter Expertise: Pick an industry and focus. This requires deep subject matter expertise beyond deep learning. This means bringing in industry leaders early in the process which greatly facilitates not only defining and addressing the problem, but also addresses trust and relationships within the industry when it’s time to go to market.
- Proprietary Data: Owning the interface allows you to instrument it and gather proprietary data. Then you are able to build high value models that drive the acquisition of additional data in that virtuous cycle of customer – application – data. You control the data value chain giving you both data dominance and pricing power. In most instances, determining how to acquire the initial data will be the most difficult aspect of this strategy.
- AI Must Deliver the Core Value: AI is not an incremental add to the solution, it is the core to unlocking a totally new opportunity. AI plus proprietary data gathered with the product itself should allow you to build increasingly attractive and valuable solutions for the industry.
If you’d like to read more from Bradford on the Vertical Strategy try this excellent article.
Is That All There Is to the Vertical Strategy?
Well no. For starters, as we pointed out in our Data Dominance article, picking the right industry with the right problems suitable for AI is no small challenge.
Although any industry that meets the criteria for the vertical strategy might be ripe for defensible exploitation, Bradford Cross adds some insight unique to the VC world.
First of all, Mr. Cross quotes that 90% of AI startups are focused on enterprise markets, not consumer apps that have been so common up to this point.
“Compared with consumer startups since 1995, enterprise startups have returned 40% more capital overall. Enterprise and consumer startups have generated equivalent IPO value, but enterprise has generated 2.5X the M&A value.” 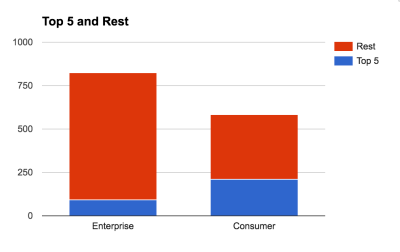
Second, market exits come in cohorts. Interest in ML and AI in the M&A market tends to occur in groupings around hot industries in which a number of viable startup targets arise together. Right now that tends to favor fintech and healthcare, followed perhaps by energy, utilities, basic industry, and transportation.
The point is simply that there are going to be more buyers in the market if you are a member of a cohort focusing on a hot industry.
Does this mean you should skip opportunities in other industries? Not at all. Just be aware that VCs are more likely to be generous with funding in favored industries than in outliers.
An Observation about Full-Stack Solutions
In general I agree with the desirability of a full-stack solution, one that provides an easy interface and solves a really important customer problem. It’s worth backing up a minute however to consider how much full-stack is enough full-stack.
Using predictive maintenance in IoT as an example, a recent BCG report listed all of the following as part of the total solution for full-stack predictive maintenance solution.
- Identifying at-risk component failure prediction.
- Optimizing resource scheduling and staffing.
- Matching technician and Inventory to the maintenance and repair work to be done.
- Ensuring tools and repair equipment availability.
- Ensuring first-time-fix optimization.
- Optimizing parts and MRO inventory.
- Predicting component fixability.
- Optimizing the logistics of parts, tools and technicians.
- Leveraging cohorts analysis to improve service and repair predictability.
- Leveraging event association analysis to determine how weather, economic and special events impact device and machine maintenance and repair needs.
As you can see, providing this full-stack solution is a tall order. Pretty much on the scale of inventing a SAP or PeopleSoft integrated ERP solution. Would this be defensible – you bet. Is this necessary in the original vision of your AI-first business solution – probably not.
As a longer-term goal this would be an ideal case but you can probably build a significant business on just 3 or 4 of these elements.
Looking back at the examples from our previous article, Blue River Technology, Axon, and Stitch Fix, these three are well on their way to defensible businesses using data dominance as their core goal. Will they grow to full-stack at some point – perhaps, but the solutions they currently offer are very high value.
What they share with the vertical strategy beyond data dominance is subject matter expertise and AI-first value creation. Full stack, however you wish to interpret that can follow so long as the application solves the immediate customer problem easily, efficiently, and accurately.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/comparing-ai-strategies-vertical-vs-horizontal.
AI with Pyramids of Self Programmable Gates
Posted on August 7th, 2018

- Posted by Vincent Granville on May 2, 2018 at 6:30am
Guest blg post by David Enríquez Arriano. For more information or to get higher pictures resolution, contact the author (see contact information at the bottom of this article.)
Introduction
This is a different approach to solve the AI problem. It is a cognitive math based on pyramids built with self-programming logic gates through learning.
A Boolean polynomial associated with a given truth table can be implemented with electronic logic gates. These circuits have pyramidal structures. Then I built pyramids accomplishing the generic form for any of these problems.
Although I can choose the balance between pure logic and pure memory in which they operate, in general, always I prefer to use the maximum cognitive power mathematically possible.
The result is an algorithmic that makes you feel as teacher in front of another human infinitely intelligent who learns looking for the logic that might exist in the patterns (input, output) fed in training.
This cognitive math allows continuous learning, immediate adaptation to new tasks and focus on target concepts. It also allows us to choose the degree of plasticity, also to implement control and supervision systems, although all of this it is fully self-regulated and self-scalable automatically if we desire so.
It is an absolutely simple and fundamental algorithm. This algorithmic extends the forties foundations of modern computing to its maximum possible.
At this level of pyramids everything is more crystallographic or mineral than biological. I use several of these pyramids and a few more pieces to build an artificial neuron. But the power of these pyramids is so great that for now I have not needed to build neurons and much less networks of them, although I know perfectly how to do it, why and for what it would be appropriate to take that step.
Experimental example of crystallographic evolution of cognitive structure in the pyramid; here pyramids pointing down:
One simple example in EXCEL, here pyramids pointing down:
This algorithmic allows or nesting or embedding cognitive structures already learned in other new majors. I have detected possibilities of certain recombination of structures to generate others, but it is something that I have yet to explore in more depth.
This algorithm works in binary and with two-dimensional pyramids because I have proven that it is the way to achieve the greatest possible cognitive power, although it can be operated in any other base and dimension at the cost of losing cognitive power.
Here is an example of one layer with four inputs binary gates in 3D square based pyramids that allows implementing them without having to use the corresponding 4D tetrahedrons. Four of these gates will feed one gate on next layer:
Here is another example of two layers with three inputs binary gates in 3D triangular based pyramids that allows implementing them building the corresponding 3D tetrahedrons. Again, here three of these gates in one layer will feed one gate in the next layer:
But I repeat, in binary and with two-dimensional pyramids the efficiency is the best, and it is so enormous that it can be computed on any mobile device, although a World Wide Web online service can easily be offered by keeping the algorithms secret on one’s own servers.
The transmission of the cognitive structure is also enormously effective in terms of the amount of information that needs to be transmitted: simple short strings of characters.
In addition everything is encrypted in itself by definition of the algorithm, because the pyramids only see zeros and ones in their inputs and give outputs following their learned internal logic, but they do not necessarily have to know what they refer to. Actually, only the user, may be a robot, will use and know the data meaning.
This math establishes a distance metric in an n-dimensional binary space that allows any learning to be optimized automatically. In addition we will use progressive deepening in the cognitive learning but always on the entire incomplete data space which configures a landscape of data, a physical map in which the best teacher guides from general cognition to concrete one, deepening progressively.
Basic graph for the generalization of contiguity metric on patterns distance for dimensions upper to three:
First order transitions table for the fundamental and simplest binary gate with two inputs.
Graph of all the possible state transitions bit to bit on the simplest gate:
Actually these 16 states on this 2D circle are the vertices of 4D hypercube on the binary B4 hyperspace. To configure the data physical map, we humans mark the importance of data mainly with life emotions. We can use some more pyramids to program the same emotional response and imprint it on any of these pyramids structure, or choose any other criteria to do so.
All of this is already finished and experienced. Examples shown in this blog are built in a bare spreadsheet, but for large-scale implementation I choose:
This cognitive math allows quickly evaluating and correcting all current AI techniques. It is really handy for any researcher or AI developer.
STEPS 1 and 2 do not require more than 2 to 4 hours/person of programming and debugging. STEP 3 can take up to 1 month/person programming depending on the use you want for this technology.
This cognitive math is already finished, so no further investment is necessary in this regard. May be you or your company would like to plan other future actions to further explore the enormous implications and their application in all other areas of knowledge. If so, please, don’t hesitate to contact me. I have contrasted this technology, but it will not be completely published.
Multidisciplinar Math
I have been decades reviewing AI works everywhere; as usual, it is not casual that I covered so many areas in so many disciplines.
Now, I can tell some main keys: When you feed a new pattern to these pyramids, mathematically far away from the clouds of previous patterns, the logic previously learned normally exploits; visually, logic crystals explode like supernovas. This also happens in humans when confronting anything far from the previous knowledge. But my pyramids always preserve intact as much as possible of the pre-learned logic even on this “catastrophic” situation. At first I thought this was a big problem, an error, then, mathematically, I understood it has to be this way. The math itself was guiding me. Only a good teacher can avoid this catastrophic event using progressive learning. The metric defined on this Bn space math allows such progression.
To create all of this on AI, I went through many walls of misunderstanding like that supernova like explosion. But again, I learned to be taught by this new cognitive math.
In sciencie many times we don’t pay attention to those points of information very distance from the regular cloud, but it happens that those distant points usually appear to be those with new relevant information.
Multilevel Programming, Parallel Computation and Embedded Nesting
This cognitive math allows to implement “what happens if” test, or parallel self-supervision.
But as in human training, you must prepare in advance of the emergency, because when the problem appears, normally there is no time to think or to learn; if lucky, may be you will have that time later. On this regard, I’m sorry to tell you that my cognitive math is so human, but mathematically it tells me that this is the way it has to be. If not, it doesn’t work.
Anyway, these machines don’t get tired, learn faster than humans and we can easily and automatically clone the best.
The origin of my cognitive math is this: when in a chaotic system energized you implement a law of behaviour to the agents, then order appears.
Complex structures became agents for higher structures. It is fractal. The four DGTI principles that I enumerate for true AI, are always the same at any level:
- To protect and empower Diversity.
- Group target always has priority over individual one.
- Transmit and live this four principles to all agents.
- There is always an Intelligent solution to any conflict, you only need to increase perspective, vision.
The difficult part with this math is to accept the universal reality of those four principles.
One example: this technology allows putting an AI pilot learning next to any human commercial pilot in the flight cabin. Then we’ll examine those AI pilots on simulator, chose the best, file the others, and improve the learning process with clones of the best in any fly. Every AI pilot collect experience and learn, but we will choose the best exactly as we do with humans. Of course for a complex task like flying a commercial plane, or driving a car, you need a system with many modules interacting in parallel, exactly as human brain has. My math mismatches all of this.
We can always implement some big pyramids to do any whole task, but adaptation capability to optimize any solution, takes us from almost crystallographic pyramids to something much more biological: neuronals, nets, nodules… We can always implement some big pyramids to do any whole task, but adaptation capability to optimize any solution, takes us from almost crystallographic pyramids to something much more biological: neuronals, nets, nodules… But now, here we will build neuronal processing machinery based on pyramids.
After studying cellular computation layers: ADN, epigenetic, ARN, protein folding, membrane computation, intercellular communication… these pyramids cognitive math foundations could be working as at micro tubular level on living neuron body and axon, where computing logic storage seems to holds on hydrophilic and hydrophobic molecules attached to alpha and beta dimmer tubulin proteins conditioning their resonant states.
I am very sorry to say that with public state of art on neural nets, working with weights, filters and retro-propagation feedback, I feel far from building even one single artificial neuron; a lot less a net like living ones.
But to solve the actual problems on AI, there is another way with these pyramids, when there is little time to think and you need then on ongoing long term live learning as in humans. In fact our own brain does so: we can nest pyramids embedding then inside pyramids, augmenting the cognitive structure to encompass new unknown patterns. This is derived from the IV DGTI principle I found: To increase cognitive structure to avoid conflict.
We can also use my cognitive math with any other system; applying this complete new concepts bunch
I like to recall how Alan Turing succeeded on Enigma decoding when he realized that, for learning, the machine need to know if the answer given is correct or not. In real live we, and also machines, my pyramids included, only can do that testing through experience. The good thing: when you have a lot of good experience, good training, the ideas or answers than you give to any problem will tend to be better, but still you will need to test then on real live to be sure. My pyramids do so.
We can easily program my pyramids to decrease “weight” of non used logic structures through time, allowing more probable change on them when confronting new patterns in live. We can perfectly adjust that cognitive lose event in many ways or even automate a parallel control of this behaviour. My pyramids have cognitive memory and memory of the strong of those memories during learning.
On training time, as when humans dream, if something not really important is not learned, I mean important depending on interest goal and/or emotions-trauma, then the program erase it from the list of knew patterns to learn. But if it is something important, then the system is forced to add it to the previous cognitive structure. It is here where patterns far from previous knowledge can create “trauma” which only exit is the typical catastrophic even, when almost all previous knowledge is destroyed on the supernova-like explosion event. Of course, emotions, if needed at any percentage, are only another program running on parallel.
We must be careful don’t mixing fundamental cognitive computing concepts with problems or concepts regarding higher cognitive structures.
Try to calculate a quick estimation of how many logic cognitive combinations has one of my pyramids built with my logic gates, every one with 16 possible estates. Any single gate, stone of the pyramid, can be one of the 16 basic gates: AND, OR, XOR, NAND, NOR, NXOR … any of these self programming gates transiting bit by bit through learning among those 16 possible states…
When any gate need to answer and have no previous knowledge, then randomly tries 0 or 1. This solves the initial value problem, and values 0 or 1 have the same significance depending of the place and local case. But even that these pyramids work like super–Touring machines, of course, if we use exactly the same given list of those random 0 or 1, then the machine is completely replicable following always the very same path through learning as a Turing machine does. But we are lucky: random is true random, not a given list, when we need to ask for those random 0 or 1 in the program.
This math is multidisciplinary; it is a General Systems Theory. Knowing this new math implies a new state of awareness on everything.
A very important key regarding the plasticity: It is necessary to allow changes in the learned cognition to add new knowledge, even destroying almost everything when the new knowledge is far (mathematical distance) from de cloud of previous patterns. But a clone can do that process in parallel before taking the place of the previous one. This is not debility; it is the only way it works as in human brain. In humans you need to go to sleep and dream to try to add properly those new patterns, but machines using those clones don’t need to stop.
So, I don’t put my pyramids to sleep/learn experiences, I can do that with their clones.
Cognition versus Memory
My cognitive math shows how to implement pure memory or pure logic, also choosing the point of balance: pure memory versus pure logic. But I normally prefer pure logic.
Pure memory only storage the exit given to an specific input, but with no internal operational logic structure at all that relates to the logic of some other patterns. Opposite to this, my cognitive math creates that internal operative logic from the very first pattern feeded.
My pyramids only see and give zeros and ones. The meaning of those binary vectors IN and OUT doesn’t matter to my algorithm, and despite this, my pyramids always look for, and find, some internal logic in the training patterns. And, the better is the teacher then better is the cognitive logic in the pyramids.
As always asked in so many places for AI, and for many decades ago, everything needed is already implicit in this cognitive math:
- Continual learning
- Adaptation to new tasks and circumstances
- Goal-driven perception, context-mission
- Selective plasticity
- Safety and monitoring.
For this last point, safety and monitoring, I can implement surveillance pyramids automatically trained for this task running “what if” tests, but as with humans, it is always preferred to improve the supervised pyramid through training a clone when time is not a problem. Principles like follow orders from specific human must be included.
We can train specific AI personalities and behaviours when needed.
We can use what already have: vision and speech recognition; implementing with my technology the AI brain that use those capabilities. Or let my cognitive math develop those capabilities itself, anywhere at any level needed.
For further advance, I build neuronals and put then to live in a virtual membrane with valleys were more information moves so that tactism on neuronals looking for activity guides them. Obviously I pre-wire an initial structure learned/cloned from previous tests. Every neuronal circuit, and every neuronal is connected, all with all, through another membrane of transmission were waves of activity connect them all, EEG like. All of this next level is much more biological.
My pyramids learn by changing their cognitive logic. With this same technology we can recreate natural chemical neurotransmitter effects to modulate behaviour, if needed we can change or modulate the learning rules. We can also automate this modulation as we do in humans through training/education.
My math teach me that to reach higher social evolution, at some point we have to be competent collaborative instead of competent predators. I love brainstorming to cross ideas with any other groups.
Responsability
This new cognitive math works. It is pure logic, pure math. I have put to work enough models and demos. Sincerely, I think it is irresponsible to build this in any environment without the proper control of human and material resources. Who could provide such resources on this planet? At this point, I am pretty sure that everybody perfectly knows and understands the final implications of this technology.
It Works Itself
As in humans, my AI algorithm is capable of give adequate answer to patterns previously unknown, and to do it properly well if the previous training has been correct –good teachers-, exactly just like humans. But with machines, we can quickly clone and put to work the best. My cognitive math allows mathematical optimization of training. If we desire so, everything always can be made without human intervention at any moment.
It is self-scalable. It allows choosing the proper balance cognition versus memory. It uses mathematically minimum resources. Even though it can be run on any device world wide, my technology allows to preserve secret AI algorithm safe at servers.
It is pure logic, taking Boolean logic from the 40´ to the quantum level on any personal device.
Appendix to go deeper
THE TRAVEL OF LEARNING, JOURNEY OF KNOWLEDGE
We walk on the shoulders of giants. Great men who connected the information points that surround us drawing wonderful conclusions that today allow us to live as we live and, sometimes, even create new connections, new knowledge, new cognition, the real information.But perhaps these giants passed some connection, some bifurcation in the path of knowledge, some unexplored branch whose ramifications we can not find following the paths already marked.Are we capable of daring to come down from their distinguished shoulders? Do we dare to put our feet in the sand where they step and look under all those stones that no one raises? Those stones that pave the path of modern knowledge that we all take for granted. Stones, knowledge, that perhaps hide under fringes, connections, cognition, branches not yet explored.Do we dare to look at the edge of the road that we all know, and try to open other completely new paths by walking where nobody has done before? In the following lines, we are not just going to make such a trip. We will leave the highway of common knowledge, comfortable and well-behaved, that comfortably travels the valley advancing slowly and surely as the new cognitions in sight clear the way. We here abandon it, and cross country, we will climb to the top of one of the mountains that surround us, and from this vantage point, we will dare to break a small hole in the veil that often clouds our global vision. We will look through this orifice around glimpsing the many other peaks and valleys that surround us. Unknown peaks, valleys not yet explored, not even dreamed of, in any area of knowledge. With this augmented vision, this greater perspective, we will descend again to the valley, but no longer on the path by which we climb to the top. In the valley, with the new perspective acquired, we will see how the knowledge highway that we leave is still very far from the place we have reached. Then we are back to the valley, but now in the middle of the wild forest, in which there are still no roads, nor paths, nor giants on which to feel safe. And we have found great knowledge, but now we are alone and we have to find a way to advance the highway to where we are to tell everyone about the other peaks and cognitive valleys we have seen from the watchtower.
THE JOURNEY We have come down from the shoulders of the giants. We have our bare feet in the sand. We look under any of those stones that they have stepped on so many times, with us on top of them: Boole’s algebra. We form truth tables of four lines and three columns. The first two columns contain the four possible combinations of the two binary variables on which we perform a logical operation. In the third column we fill in the lines defining the type of logical operation. AND, OR, NOR, XOR… With only AND and OR and NO, we have built all modern computing. These fundamental operations are the root of all what a microprocessor knows to do, with this we do everything else going up in levels of complexity, nesting in one another. Now, we are going to expand this foundation, with the stone in our hands we look out of the way, because there are 16 logical operations or possible doors. Yes 16, and we need them all to built proper AI. Given any case of binary inputs that we feed to the “black box” that must give us an specific binary outputs, we define a truth table for that black box. We assign a column to each input variable, for each output variable we add another column to the truth table. Each line of this table represents a combination of the inputs and their corresponding output that must give us the black box that we program. Each line is a pattern: input and its corresponding output. If we do not know all the possible patterns, it can happen that at some point our black box hangs because it has faced an entry not registered in its table, an entry for which it has no output recorded in its table. Boole tells us how to write and reduce algebraic polynomials capable of operating with the inputs to give the outputs. These polynomials are a way to operate or program the black box, another way is by simple memory in the table.
Boole also tells us that to write the polynomial, we can look at the ones, doing an AND of the ones of the entries in each line of the table, and with these an OR in the ones of the column of each output. Thus we will have a Boolean polynomial for each output column. When we implement these polynomials with electronic logic gates, pyramidal structures usually appear for each output variable. A pyramid for each output variable, but all pyramids with the same input variables in its base. These pyramids usually have several logic gates in the area of their base. But the number of gates is reduced as we go through the processing of the polynomial, until we reach a single gate at the exit, at the top of the pyramid. It is logical, never better said, the base of the pyramid processes information closer to the input data, information more specific to them. But by delving into the logical processing to the output, the information is increasingly general taking into account factors of the broader inputs. Experimentally pyramids usually show, in their cognitive logic, a characteristic crystallography near their base, associable to the primary decoding of the input vector data. Can we build a generic pyramid for any given truth table? We can place the stones from the base to the top covering with each the joint of the two one in the line below. Stones underneath give input information to the stone on the superior line. We should allow these stones to be any of the 16 possible logical gates. And we’ll want to somehow self-programming through learning; we’ll care this. At the base of the pyramid, inputs of each gate or stone must have all the possible combinations of all inputs, because we want the pyramid to be generic and therefore it must always have all the possibilities of relation among all the inputs. For this we can make a two-dimensional double-entry table, with the entries in the rows and in the columns. From the matrix of possible pairs, the diagonal does not give us anything by relating each input variable with itself. We can take the combinations only of the upper triangular matrix, because they are the same as those of the lower triangular.
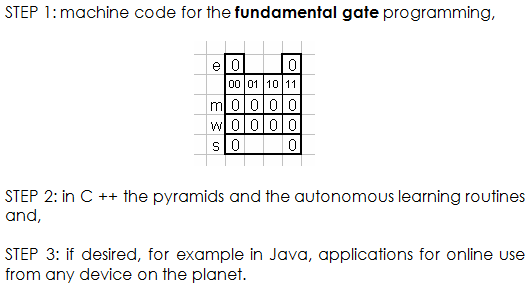
These combinations are the ones we use at the input base of the pyramid. For example, having 4 entries a, b, c, d; we will have the input gates of the base of the pyramid fed with:
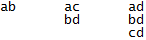
So this pyramid will have 6 gates in its base:
(4-1) + 2 + 1 = 6
In general, given n input variables, the base of the pyramid will have:
(n2 – n) / 2 gates
This number is also the number of lines of the pyramid to the exit at the top. Obviously we are working in binary and therefore with two-dimensional pyramids. We can generalize all of this in other bases, or with gates of more than two inputs, and with multidimensional pyramids. But the greatest possible connectivity and therefore the highest logical power is achieved in binary, with two-way gates and two-dimensional pyramids. However, the multidimensional exploration leads to a beautiful conclusion that relates the infinite and zero, and the balance between pure cognition and pure memory. We move in a space that I call Bn, in which each new binary variable adds a new dimension with a single point that can be zero or one. These concepts are important to get into the universe of incomplete sample spaces, in which pyramids are the program inside the black box, which will learn through experience from incomplete sets of patterns.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/ai-with-pyramids-of-self-programmable-gates.
What Comes After Deep Learning?
Posted on August 1st, 2018

- Posted by William Vorhies on March 20, 2018 at 12:55pm
- https://www.datasciencecentral.com/profiles/blogs/what-comes-after-deep-learning
Summary: We’re stuck. There hasn’t been a major breakthrough in algorithms in the last year. Here’s a survey of the leading contenders for that next major advancement.

We’re stuck. Or at least we’re plateaued. Can anyone remember the last time a year went by without a major notable advance in algorithms, chips, or data handling? It was so unusual to go to the Strata San Jose conference a few weeks ago and see no new eye catching developments.
As I reported earlier, it seems we’ve hit maturity and now our major efforts are aimed at either making sure all our powerful new techniques work well together (converged platforms) or making a buck from those massive VC investments in same.
I’m not the only one who noticed. Several attendees and exhibitors said very similar things to me. And just the other day I had a note from a team of well-regarded researchers who had been evaluating the relative merits of different advanced analytic platforms, and concluding there weren’t any differences worth reporting.
Why and Where are We Stuck?
Where we are right now is actually not such a bad place. Our advances over the last two or three years have all been in the realm of deep learning and reinforcement learning. Deep learning has brought us terrific capabilities in processing speech, text, image, and video. Add reinforcement learning and we get big advances in game play, autonomous vehicles, robotics and the like.
We’re in the earliest stages of a commercial explosion based on these like the huge savings from customer interactions through chatbots; new personal convenience apps like personal assistants and Alexa, and level 2 automation in our personal cars like adaptive cruise control, accident avoidance braking, and lane maintenance.
Tensorflow, Keras, and the other deep learning platforms are more accessible than ever, and thanks to GPUs, more efficient than ever.
However, the known list of deficiencies hasn’t moved at all.
- The need for too much labeled training data.
- Models that take either too long or too many expensive resources to train and that still may fail to train at all.
- Hyperparameters especially around nodes and layers that are still mysterious. Automation or even well accepted rules of thumb are still out of reach.
- Transfer learning that means only going from the complex to the simple, not from one logical system to another.
I’m sure we could make a longer list. It’s in solving these major shortcomings where we’ve become stuck.
What’s Stopping Us
In the case of deep neural nets the conventional wisdom right now is that if we just keep pushing, just keep investing, then these shortfalls will be overcome. For example, from the 80’s through the 00’s we knew how to make DNNs work, we just didn’t have the hardware. Once that caught up then DNNs combined with the new open source ethos broke open this new field.
All types of research have their own momentum. Especially once you’ve invested huge amounts of time and money in a particular direction you keep heading in that direction. If you’ve invested years in developing expertise in these skills you’re not inclined to jump ship.
Change Direction Even If You’re Not Entirely Sure What Direction that Should Be

Sometimes we need to change direction, even if we don’t know exactly what that new direction might be. Recently leading Canadian and US AI researchers did just that. They decided they were misdirected and needed to essentially start over.
This insight was verbalized last fall by Geoffrey Hinton who gets much of the credit for starting the DNN thrust in the late 80s. Hinton, who is now a professor emeritus at the University of Toronto and a Google researcher, said he is now “deeply suspicious” of back propagation, the core method that underlies DNNs. Observing that the human brain doesn’t need all that labeled data to reach a conclusion, Hinton says “My view is throw it all away and start again”.
So with this in mind, here’s a short survey of new directions that fall somewhere between solid probabilities and moon shots, but are not incremental improvements to deep neural nets as we know them.
These descriptions are intentionally short and will undoubtedly lead you to further reading to fully understand them.
Things that Look Like DNNs but are Not
There is a line of research closely hewing to Hinton’s shot at back propagation that believes that the fundamental structure of nodes and layers is useful but the methods of connection and calculation need to be dramatically revised.
Capsule Networks (CapsNet)

It’s only fitting that we start with Hinton’s own current new direction in research, CapsNet. This relates to image classification with CNNs and the problem, simply stated, is that CNNs are insensitive to the pose of the object. That is, if the same object is to be recognized with differences in position, size, orientation, deformation, velocity, albedo, hue, texture etc. then training data must be added for each of these cases.
In CNNs this is handled with massive increases in training data and/or increases in max pooling layers that can generalize, but only by losing actual information.
The following description comes from one of many good technical descriptions of CapsNets, this one from Hackernoon.
Capsule is a nested set of neural layers. So in a regular neural network you keep on adding more layers. In CapsNet you would add more layers inside a single layer. Or in other words nest a neural layer inside another. The state of the neurons inside a capsule capture the above properties of one entity inside an image. A capsule outputs a vector to represent the existence of the entity. The orientation of the vector represents the properties of the entity. The vector is sent to all possible parents in the neural network. Prediction vector is calculated based on multiplying its own weight and a weight matrix. Whichever parent has the largest scalar prediction vector product, increases the capsule bond. Rest of the parents decrease their bond. This routing by agreement method is superior to the current mechanism like max-pooling.
CapsNet dramatically reduces the required training set and shows superior performance in image classification in early tests.
gcForest
In February we featured research by Zhi-Hua Zhou and Ji Feng of the National Key Lab for Novel Software Technology, Nanjing University, displaying a technique they call gcForest. Their research paper shows that gcForest regularly beats CNNs and RNNs at both text and image classification. The benefits are quite significant.
- Requires only a fraction of the training data.
- Runs on your desktop CPU device without need for GPUs.
- Trains just as rapidly and in many cases even more rapidly and lends itself to distributed processing.
- Has far fewer hyperparameters and performs well on the default settings.
- Relies on easily understood random forests instead of completely opaque deep neural nets.
In brief, gcForest (multi-Grained Cascade Forest) is a decision tree ensemble approach in which the cascade structure of deep nets is retained but where the opaque edges and node neurons are replaced by groups of random forests paired with completely-random tree forests.
Pyro and Edward
Pyro and Edward are two new programming languages that merge deep learning frameworks with probabilistic programming. Pyro is the work of Uber and Google, while Edward comes out of Columbia University with funding from DARPA. The result is a framework that allows deep learning systems to measure their confidence in a prediction or decision.
In classic predictive analytics we might approach this by using log loss as the fitness function, penalizing confident but wrong predictions (false positives). So far there’s been no corollary for deep learning.
Where this promises to be of use for example is in self-driving cars or aircraft allowing the control to have some sense of confidence or doubt before making a critical or fatal catastrophic decision. That’s certainly something you’d like your autonomous Uber to know before you get on board.
Both Pyro and Edward are in the early stages of development.
Approaches that Don’t Look Like Deep Nets
I regularly run across small companies who have very unusual algorithms at the core of their platforms. In most of the cases that I’ve pursued they’ve been unwilling to provide sufficient detail to allow me to even describe for you what’s going on in there. This secrecy doesn’t invalidate their utility but until they provide some benchmarking and some detail, I can’t really tell you what’s going on inside. Think of these as our bench for the future when they do finally lift the veil.
For now, the most advanced non-DNN algorithm and platform I’ve investigated is this:
Hierarchical Temporal Memory (HTM)
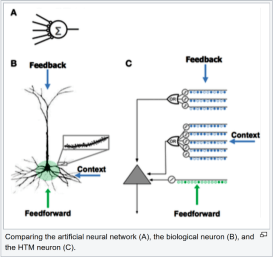
Hierarchical Temporal Memory (HTM) uses Sparse Distributed Representation (SDR) to model the neurons in the brain and to perform calculations that outperforms CNNs and RNNs at scalar predictions (future values of things like commodity, energy, or stock prices) and at anomaly detection.
This is the devotional work of Jeff Hawkins of Palm Pilot fame in his company Numenta. Hawkins has pursued a strong AI model based on fundamental research into brain function that is not structured with layers and nodes as in DNNs.
HTM has the characteristic that it discovers patterns very rapidly, with as few as on the order of 1,000 observations. This compares with the hundreds of thousands or millions of observations necessary to train CNNs or RNNs.
Also the pattern recognition is unsupervised and can recognize and generalize about changes in the pattern based on changing inputs as soon as they occur. This results in a system that not only trains remarkably quickly but also is self-learning, adaptive, and not confused by changes in the data or by noise.
Some Incremental Improvements of Note
We set out to focus on true game changers but there are at least two examples of incremental improvement that are worthy of mention. These are clearly still classical CNNs and RNNs with elements of back prop but they work better.
Network Pruning with Google Cloud AutoML
Google and Nvidia researchers use a process called network pruning to make a neural network smaller and more efficient to run by removing the neurons that do not contribute directly to output. This advancement was rolled out recently as a major improvement in the performance of Google’s new AutoML platform.
Transformer
Transformer is a novel approach useful initially in language processing such as language-to-language translations which has been the domain of CNNs, RNNs and LSTMs. Released late last summer by researchers at Google Brain and the University of Toronto, it has demonstrated significant accuracy improvements in a variety of test including this English/German translation test. ![]()
The sequential nature of RNNs makes it more difficult to fully take advantage of modern fast computing devices such as GPUs, which excel at parallel and not sequential processing. CNNs are much less sequential than RNNs, but in CNN architectures the number of steps required to combine information from distant parts of the input still grows with increasing distance.
The accuracy breakthrough comes from the development of a ‘self-attention function’ that significantly reduces steps to a small, constant number of steps. In each step, it applies a self-attention mechanism which directly models relationships between all words in a sentence, regardless of their respective position.
A Closing Thought
If you haven’t thought about it, you should be concerned at the massive investment China is making in AI and its stated goal to overtake the US as the AI leader within a very few years.
In an article by Steve LeVine who is Future Editor at Axios and teaches at Georgetown University he makes the case that China may be a fast follower but will probably never catch up. The reason, because US and Canadian researchers are free to pivot and start over anytime they wish. The institutionally guided Chinese could never do that. This quote from LeVine’s article:
“In China, that would be unthinkable,” said Manny Medina, CEO at Outreach.io in Seattle. AI stars like Facebook’s Yann LeCun and the Vector Institute’s Geoff Hinton in Toronto, he said, “don’t have to ask permission. They can start research and move the ball forward.”
As the VCs say, maybe it’s time to pivot.
AI and the future of work
Posted on July 31st, 2018
Fueling the AI revolution with gaming
Posted on July 28th, 2018

Alison B Lowndes AI DevRel | EMEA – NVIDIA
After spending her first year with NVIDIA as a Deep Learning Solutions Architect, Alison is now responsible for NVIDIA’s Artificial Intelligence Developer Relations in the EMEA region. She is a mature graduate in Artificial Intelligence combining technical and theoretical computer science with a physics background & over 20 years of experience in international project management, entrepreneurial activities and the internet.
She consults on a wide range of AI applications, including planetary defence with NASA, ESA & the SETI Institute and continues to manage the community of AI & Machine Learning researchers around the world, remaining knowledgeable in state of the art across all areas of research. She also travels, advises on & teaches NVIDIA’s GPU Computing platform, around the globe
Abstract
Artificial Intelligence is impacting all areas of society, from healthcare and transportation to smart cities and energy. AI won’t be an industry, it will be part of every industry. NVIDIA invests both in internal research and platform development to enable its diverse customer base, across gaming, VR, AR, AI, robotics, graphics, rendering, visualization, HPC, healthcare & more.
Alison’s article will introduce the hardware and software platform at the heart of this Intelligent Industrial Revolution: NVIDIA GPU Computing. She’ll provide insights into how academia, enterprise and startups are applying AI, as well as offer a glimpse into state-of-the-art research from world-wide labs & internally at NVIDIA, demoing, for example, the combination of robotics with VR and AI in an end-to-end simulator to train intelligent machines. Beginners might like to try our free online 40-minute class using GPU’s in the cloud: www.nvidia.com/dli
Introduction
My name is Alison and I am with NVIDIA. My field is actually artificial intelligence. I went back to university as a mature student, so I concentrated a lot more than most people. What I’m going to do is to explain who Nvidia are why I joined them. Why we’re all over artificial intelligence and also just give you some details on our software, hardware future plans. My first year with Nvidia was basically as a deep learning Solutions Architect across all of these major verticals. This is pretty much daily life for the whole of the of the world and what that allowed me to do on a consulting role was a massive great deal of Applied deep learning. understanding AI permeates everything that both we and all our customers do across gaming, graphics, virtual reality, augmented reality, simulation and medical bioinformatics. Even planetary defense so I wear many hats.




I’m most proud of the frontier development lab. Basically NASA came and said that despite everything that they are capable of doing that they really needed help on AI. Really important in today’s age is cross collaboration, cross discipline collaboration so it’s combining their skill sets in planetary science with skill sets of data scientists and coders like yourselves. nvidia pioneered a new form of computing and this is a new form of computing that’s loved by most of the world’s most demanding users which is gamers. Also scientists and designers and and it’s fueled by this insatiable demand for better and better 3d graphics. For much more realism and so we evolved the GPU into this computing brain. We invented it NVIDIA was formed in 1993. We invented it and introduced it to the world in 1999 and this sparked the growth of the of the PC gaming market which is actually now worth over a hundred sorry billion dollars. Gaming is now over 60 percent of our revenue despite the fact that we’ve pretty much turned our focus to to AI completely.




Super Computing
We continuously reinvent ourselves, we have to. Adaptability is absolutely key to survival in today’s world. You have to be able to just pivot and adapt to it. To what’s being done and coding makes that really simple. We were already working with every car company out there so it was easy for us to pivot to the self-driving car side because they were already using us for infotainment and for visual and as well as the actual design space, VR as well. Obviously GPUs help with this. Our supercomputer capability goes worldwide across US, Japan and Europe. We are a learning machine ourselves that constantly evolves to solve problems that really matter to the to the world. Sheer physics and mathematics, AI can actually predict tornadoes but below is the Oklahoma finger of God that killed 24 people and injured over 350 other people and but what we’re doing here is we’re actually simulating it. The actual simulation itself takes takes upwards of supercomputer capability something called RVCA and eight of them. Digital globe and recon just a few months back demoed this in 3d and in virtual reality. Can you imagine being able to walk through a live tornado simulation. I mean this is basically the the state of play now.
Essentially the year before, a similar disruptive force was just starting to build strength. I’m a massive fan of Feynman. I studied a bit of physics and Feynman. this is a Feynman diagram that basically shows the coming together of the GPU. All the data that we’re providing as a society which is key and the other integral which is the existing algorithms that we already had. It’s really important to understand the the definitions. You hear a whole load of hype about AI and a lot of it, thanks to the movies, is not true. We don’t have terminators yet but it’s really important that you understand so AI actually inlogic and rule-based learning as well as machine learning. Machine learning itself is this subset of deep learning. Deep just means it’s got more than two hidden layers. There’s a few other intricacies but they are related but they’re definitely not equivalent.




Neural Networks
The timeline here is really important as well this is not new technology basically it started in 1956. It’s something called the Dartmouth conference where it was Claude Shannon and a group of friends that put together this term artificial intelligence. They actually thought that they could probably solve it that summer as well but here we are now. If you don’t know the GPU the graphics processing unit which is NVIDIAs lifeblood is a coprocessor you still need the CPU. You’re just passing on the actual part of code that can be parallelized. We even have things called open ACC where you can literally shunt the parallelized sections, for example existing legacy code and then this leaves and frees up the CPU to take on its it’s typical serial jobs and running os’s etc.




CUDA
I don’t have time to actually go into the the intricacies of CUDA but we’ve got a stack of resources online and we run a very technical blog. CUDA itself is at the heart of AI because it’s at the heart of our room GPUs. Even Intel, if you look at some of the publicity that’s going around today it seems to be pivoting that way. Without guys and girls like you people reading the industry has no chance whatsoever in harnessing AI so again take a further look. Take some more courses and pivot towards this because AI is now central even to the people who don’t know it yet. To every single business that is out there today it’s probably the most profound thing since the transistor was invented. There is a whole lot that can that can happen and what you have to realize is that once you actually get the hang of deep learning or AI or any of the hype terms, that you’re here, this will actually help you in your job.





It’s about getting great coders into the workplace and also letting you sort of run free. AI is going to take a lot of the laborious tasks away from us and allow us lots and lots of time to to play in sandbox areas. To even break things and do what humans do really well which is get creative. When you start getting creative in code you can do some incredible things. I’m going to do a quick 101 on deep learning for those that actually don’t know it, so try and think about the differences between these two bikes so that’s my first-ever GSXR 750 on the left and this of course is the Ducati Monster.
What a computer will basically do is try and translate these images into pixels into maths into vectors and work out the actual differences on a pixel level. It will actually be able to capture things that we would never have thought about. It will pick up nuances about backgrounds. Like it has an aliens eyes that have been used to look at every single problem that humanity currently has. The problem that is to actually teach an AI system you have to have a large label data set for supervised learning and as far as I know we don’t yet have a data set like that.




I could go and perhaps create a million pictures of motorbikes off Google but then I would have to label each one. It was things like Stanford running the imagenet competition and the large part of that workload was actually labeling the data but I’m currently working with samasource. Samasource are literally pulling people out of slums in Kenya and India and teaching them how to help us provide these kind of data services like labeling data. It’s really quite profound so basically you’ve got things like like regression where you could take a million data points and and divide them up into a line but drawing that line through the data set you you still need something called a loss function. This measures how rubbish your system is at making a prediction and the key is to converge on a solution that’s acceptable. That’s to a certain level of accuracy and that depends on the actual applications themselves. Now the work course behind that is gradient descent.




Chris Ola of Google’s work, it’s a really cool way of reading papers and reading research papers is a really great way to actually keep up with this with this field. Take a look at this still so scary maths diagram but training a neural network is is all about trying to find a good minimum on an error. Surface deep learning systems, what they’re doing is they are just exploring through huge huge problem spaces and as humans we can’t cope with anything more than 3d maybe 4d and we’re at very very high dimensional capability here so we need AI to help us through this. To convert into maths and we need computers to actually do the computation and GPUs and they’re the workhorse they they take the brunt of it.




Deep Learning
Deep learning is split between two workloads. You have the computationally intensive training part, where although this is based on the on the brain itself, you’re in a supervised learning setup and feeding in lots and lots of labeled data. Once you actually got to a situation where you’ve actually trained and you’ve reached the end the accuracy that you want to get you have something called inference. An inference is basically just doing the forward path so you’re not doing forward backward and change the weights then repeating this process. You’re just doing the forward path so it’s very simple and this is how you can have it deployed on things like a mobile a mobile phone. Again I don’t have enough time to go deep into it but one thing you have to realize is that the world is not static. Images are great. Convolutional neural networks are very very good at working on static problems like like image recognition, but for everything else, which is dynamic, we need recurrent neural networks so things like speech recognition and pattern recognition in sequence looking at lots and lots of historical data.




Recurrent neural networks
Recurrent neural networks are really vital because they they grasp the structure of data dynamically over time. There were several problems with implementation but basically this was over 25 years ago and a guy named Sepp Hochreiter who was actually the first PhD of jurgen schmidhuber who is now director with a Swiss AI lab in Lugano Switzerland. Sepp Hochreiter solved the problem and he created something called long short-term memory, which is used throughout every kind of AI dynamic problem that you actually see today. I’m proud to know him and his team are also working on healthcare problems. They’re winning things like the tox 21 challenge where you can take deep learning and assess and how toxic various chemicals are to humans. Take a look at his paper from from it as it’s a really good one because it gives you an indication of the real understanding of deep learning and how networks represent layer by layer.





Otto Friedrich Karl Deiters (German: November 15, 1834 – December 5, 1863) was a German neuroanatomist. He was born in Bonn, studied at the University of Bonn, and spent most of his professional career in Bonn. He is remembered for his microscopic research of the brain and spinal cord.
Around 1860, Deiters provided the most comprehensive description of a nerve cell that was known to exist at the time. He identified the cells’ axon, which he called an “axis cylinder”, and its dendrites, which he referred to as protoplasmic processes. He postulated that dendrites must fuse to form a continuous network.
This diagram was drawn in 1865 by a guy called Otto Dieters and it’s showing the human nerve cell body. There and all the synapses and dendrites that actually come off. There is a huge body of work now that is mapping together neuroscience and AI. Geoff Hinton considered one of the godfathers of AI who’s actually bristol born but now he’s in montreal. They’re changing the way that that we use layers instead of just multi layer they’re putting layers within layers and this basically allows you to to map a whole lot of more data. More information at a cellular level and again i don’t have time to get into this but this is the really key thing whatever the architecture that you are using, convolutional, neural networks, recurrent, etc. The real power comes from these AI systems. There is nothing more powerful than a human being that’s assisted or augmented by AI. I prefer the term augmented intelligence than artificial intelligence because what it does is it brings us to to what I consider the next stage.




Reinforcement learning
The software is reinforcement learning or the theory is reinforcement learning. The hardware is both the GPUs that are running this and the CPUs but also what we’re deploying into which is robotics of varying shapes and forms both physical and virtual. So everybody has heard about alphago. This was reinforcement which combined dynamic programming and also supervised learning. Alphago zero now doesn’t even need that supervised learning part. It made a lot of headlines by saying that it was doing everything itself. Now when you actually go behind the scenes it couldn’t do anything without coders like you. Whether or not you’re working for Google, it makes no difference without the coders. Reinforcement learning basically is about learning a policy or the best next move to make, and this is across the board and but the key thing is that alphago zero whether it’s doing it entirely on its own or not still can’t play knots and crosses. It can’t play anything other than go so what they needed to do and this was a huge engineering effort.




Deep mind have their own deep mind lab. They needed to provide an environment where the AI agents could actually learn generalization. They could learn to play lots of other different games at the same time and games engines provide an infinite amount of training data. Deep minds latest work is where and I actually learned the word parkour. I’d never heard of the word parkour before but basically it is being able to do lots and lots of different actions like jumping running etc. It’s doing all this by itself. It’s actually learning to do the running and the jumping without any prior instructions whatsoever.
Imitation Learning
Imitation learning is another thing so this is where you you show a robot how to do something only once and this of course is getting close to how we learn. You need to see it twice or three times but ultimately we don’t need to see something a thousand times to actually do it. A researcher Berkeley left and along with them some other people he’s formed a company called embodied intelligence where he literally wants to work on just this. Since then this field has just exploded. I know because I kind of live right in the middle of everything and it’s part of my job to try and cover the research and and stay up with the actual progress. It’s drug design, it’s it’s astronomy, it’s use cases all over the place. I don’t have time as much as I would love to, to go into every single use case. Just in health care alone there is a plethora and there’s some really impactful work going on by harnessing AI. Deep Learning Toolkit (DLTK) is by Imperial College and it’s just a really great toolkit if you are working in the medical space.
This is Jamie by a company called Soul machines, founded by Mark Sagar. He’s responsible for avatar and the technology behind that and also won Oscars for King Kong. What he basically did was he got Cate Blanchett on board and recorded lots and lots of her dialogue and they’ve coupled together with a huge health insurance company in Australia to create this avatar that individuals can use. The Avatar talks to you just the same as Siri would but its actually got a face. She can actually read and understand emotion in voices. It’s an ongoing learning cycle as I’ve got the the the Samsung here, called their assistant Bixby and it tells you over and over again that it’s still learning. The more I use it the better it will be but there we go.




Even unity3d now has an AI lab and here’s a tip. Take a look dopamine games because they’re doing some very very cool stuff considering they’re actually on the smaller end of games out games houses. EAS CEO Andrew Wilson was was recently talking about the fact of feeding an AI system every acting performance in all war films we’ve ever had. Feed that into the actual system. How much is that going to improve the game? how much is it going to improve your experience? Putting AI into characters as well. The game studio respawn is responsible for things like titanfall, so you’re going to start to see AI in those games very very shortly and of course we’re all over this. We have been for quite a few years. We recently launched holo deck simply because we’re already doing lots of work in rendering photorealistic levels. We’re already talking to the car manufacturers and we’ve already been working with them for decades. This is about being able to get together with your collaborators wherever they are in the world put on a VR headset and you’re there with a full res setup of whatever you’re actually working on. This is a supercar that we actually demoed but built on built on the back of this is is Isaac. Isaac is a robotics learning platform that incorporates reinforcement learning as well as any robot that you want to put in there.




In 2013 I was working with the National Nuclear laboratory and we were coding a virtual robot. Controlling it with just an Xbox controller. So you can bring anything into this platform, teach it, get a trained system and then deploy it in a real robot. This is just a screenshot of Isaac in the nursery that we built within the holo deck and in there it can actually interact with you and play Domino’s and learn from you all using reinforcement learning. We’re only just scraping the surface here. We’re only in beta access but there are so many different opportunities here and of course the ultimate robot which we’ve been working on for quite a few years. Although this is a slightly different problem set because of course you’re talking about collision avoidance. With robots it’s all about touch, grasp and and haptics. The problem with this is the rest of the world that is so complex that we literally had to put together a whole new chipset. We put this together on various iterations starting with Drive px2 and and then we went to Xavier on the actual chipset.




The Pegasus chip is now capable of 320 Tflops, that’s trillion operations per second. It’s capable of perceiving the world through high res. It’s capable of 360 degree surround cameras localizing the the actual vehicle within centimeter accuracy but this is such a huge problem space that we want to see the fastest possible adoption of AI technology. We can’t address everything so we open-source the actual deep learning accelerator part of this chipset. We’re also right across the high-performance computing scenario and to prove that we have over 500 GPU ready apps. You can actually go to look at them and I don’t have time to list those 500 but it’s across each of those verticals in the slide right at the beginning.




Just to give you an indication now of how we enable people, all our software is free. You simply just go online to developer NVIDIA .com and we work with every single framework so the frameworks are basically the building blocks. They’re the way of, literally in some cases in natural language, creating the layers of the neural network that you’re going to use in code. There are over 60 different frameworks but there’s probably a top ten. We work with as many as we possibly can. I don’t really want to recommend but cafe 2 is really rocking well at the moment. I personally started in torch so PI torch of course is a big favorite of mine. We work with all the teams directly. Apache and Amazon are widely used and so they’re really good if you’re looking for which framework out of those 60-odd. There’s lots of information online but basically all our software is free just go to developer.android.com and sign up. To actually gain from CUDA, the programming language for the GPU (launched it in in 2006) this is exactly why you’re seeing a revolution in AI now. It’s because people are able to program the GPUs.




Deep Learning Frameworks

Caffe2
Caffe2 is a deep-learning framework designed to easily express all model types, for example, CNN, RNN, and more, in a friendly python-based API, and execute them using a highly efficiently C++ and CUDA back-end. Users have flexibility to assemble their model using combinations of high-level and expressive operations in python allowing for easy visualization, or serializing the created model and directly using the underlying C++ implementation. Caffe2 supports single and multi-GPU execution, along with support for multi-node execution.
![]()
Cognitive ToolkitThe Microsoft Cognitive Toolkit, formerly known as CNTK, is a unified deep-learning toolkit that describes neural networks as a series of computational steps via a directed graph. In this directed graph, leaf nodes represent input values or network parameters, while other nodes represent matrix operations upon their inputs.

MATLABMATLAB makes deep learning easy for engineers, scientists and domain experts. With tools and functions for managing and labeling large data sets, MATLAB also offers specialized toolboxes for working with machine learning, neural networks, computer vision, and automated driving. With just a few lines of code, MATLAB lets you create and visualize models, and deploy models to servers and embedded devices without being an expert. MATLAB also enables users to generate high-performance CUDA code for deep learning and vision applications automatically from MATLAB code.

MXNetMXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix the flavors of symbolic programming and imperative programming to maximize efficiency and productivity.In its core is a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. The library is portable and lightweight, and it scales to multiple GPUs and multiple machines.

NVIDIA CaffeCaffe is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors. NVIDIA Caffe, also known as NVCaffe, is an NVIDIA-maintained fork of BVLC Caffe tuned for NVIDIA GPUs, particularly in multi-GPU configurations.

PyTorchPyTorch is a Python package that provides two high-level features:Tensor computation (like numpy) with strong GPU accelerationDeep Neural Networks built on a tape-based autograd systemYou can reuse your favorite Python packages such as numpy, scipy and Cython to extend PyTorch when needed.

TensorFlowTensorFlow is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture lets you deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code. For visualizing TensorFlow results, TensorFlow offers TensorBoard, suite of visualization tools.

ChainerChainer is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach, also known as dynamic computational graphs, as well as object-oriented high-level APIs to build and train neural networks. It supports CUDA and cuDNN using CuPy for high performance training and inference.

PaddlePaddlePaddlePaddle provides an intuitive and flexible interface for loading data and specifying model structures. It supports CNN, RNN, multiple variants and configures complicated deep models easily.It also provides extremely optimized operations, memory recycling, and network communication. PaddlePaddle makes it easy to scale heterogeneous computing resources and storage to accelerate the training process.
NVIDIA Deep Learning SDK
The NVIDIA Deep Learning SDK provides powerful tools and libraries for designing and deploying GPU-accelerated deep learning applications. It includes libraries for deep learning primitives, inference, video analytics, linear algebra, sparse matrices, and multi-GPU communications.






Graph analytics is across the board on many massive problem sets. So we’ve sped all that up with with MV graph and a visualization tool. When I was doing research in University I was just command-line and getting all my input from the from the very good output that’s given from torch and but then digits came along and you get to see exactly what’s going on in the actual layers. You get a visualization. You get a graphical understanding of the of the accuracy and how the loss is going. There’s also now a ton of pre trained models for data curation in the problem set. This is actually the majority of the work. It’s like 70% of the work. The AI side, you can just pick a pre-trained model and the job is done so as I said tensor RT is is for vastly faster inference.




Deep stream is for if you do an intelligent video analysis and a lot of people are. On the hardware side we are spending literally billions to actually get the best that we possibly can. The recent launch, which was Walter, is 21 billion transistors. We are at the limit now. We are right at the edge of what is possible. What we’ve had to do is is make fine tunings right down at the instruction set to actually provide even more speed up. When you’re talking about using tensor RT these are the differences in just up from just our previous chip which was Pascal.




AlexNet which is which is a type of convolutional neural network is a lot bigger now so it creates a lot more demand. The tensor core as I said has this brand new instruction set. AI is pretty much just matrix multiplication and accumulate or summation. That is really at the heart of it so what we did is we we managed to do the 4 by 4 multiply simultaneously and that in itself gives you 12 times the actual throughput already. The the tensor cores are part so there’s actually 640 of them with the over 5,000 cores that are now on our voltage chips. All that sounds great but how do you actually really cope with with massive problems? What we do is we put multiple cards into one unit. The dgx family was actually launched back in 2016 and this is eight high-end cards with our own interconnects because PCIe just doesn’t cut it anymore. We have our own interconnect called MV link.




We’ve containerized all that software I’ve spent the hours and hours trying to get all the dependencies together to actually do deep learning work. We’ve put it all now inside containers optimized to all the major frameworks and onboard dgx. It’s now Volta and what’s really important is that the software is optimized. You simply login to the system. It’s actually designed to do tasks very quickly. Pascal is a hundred and seventy teraflops so trillion floating point operations and voltages just blown that out of the window.
This is addressing the simple fact that there are teams of people who are now working on these problems and so it’s the ability with containers. At the moment it’s docker but we are looking at all the other use cases because the HPC will prefer things like singularity. Kubernetes is is very popular so we’re looking at all that and we’re implementing it as fast as we can. Dgx is actually a server so obviously it needs to be rack mounted if you don’t have that capability you can actually now get a desk side version with Volta. This is actually for cards, it’s water-cooled so it’s nice and quiet. Dgx the server is not quiet because you’ve got eight massive cards doing a lot of work.




Alternatively you can now access Walter right now via Amazon Web Services up in the cloud. We have something called NGC or the NVIDIA GPU cloud where you have the the capability in three simple steps to sign up. You can either choose to use the cloud or choose to use local compute. If you’ve got some of our geforce cards or you have dgx and then you simply just pull one of these containers down. We have an entire registry of containers now for all of the of the frameworks. All other possible combinations and versions of Cuda etc but the the the real key here is everything’s up to date. There’s no more going through the whole rigmarole. You’d simply just just click on that up-to-date container and it really just makes life a lot easier. We build the products for training things like dgx and we build the products for inferencing. That’s in the data center like our Tesla cards.

There is this other part and that’s inference and this is this is huge. I mean this is in billions of cameras, billions of edge devices. We actually have no idea how big this problem is going to be but we have to address it now. This is just some of the actual use cases that we’re dealing with on on a daily basis. So of course we need an embedded GPU and we have a credit card size GPU called Jetson now tx2. The version that is capable of between one and one and a half trillion floating point operations per second in a credit card space and there’s lots and lots of people using this for various use cases. You can actually buy it very cheaply in a dev kit formats. Its got loads of IO, it’s got a camera on board, or if you’re in academic we actually give them away with an entire robotics and embedded teaching kit alongside.


TX 2 Development Kit
So we have these these teaching kits that we’ve worked with NYU and young laocoon as well specifically for deep learning. Servo city work with us on on these teaching kits. There is this entire embedded space. There’s $11,000 Nvidia but that’s not a big enough market so we have to put the entire embedded space online. That means you can get every single piece of information and the hardware purely via the website. Including jetpack and if I wrote another article that would not be enough to tell you all about the the various parts of jet pack and what it can do. Everything that we try to do is is so that you can develop and deploy right across the same architecture. That’s hardware architecture with the same software that you’ve been using and prototyping on.
We do so much training now that we developed something called the deep learning Institute and this is using ipython or Jupiter notebooks so you can do hands-on coding on our GPUs in Amazon Web Services right now. We also work with Microsoft Azure and our GPUs are in every cloud provider that there is so this will eventually branch out. We have over 200 different classes you can go online to that website now and do at least three of those for free. Hands-on coding in an in a variety of different frameworks. You just go on to a setup called quick labs which was actually bought by Google. Google’s entire cloud platform is going to be accessible via quick labs.
About 200 different use cases and there’s there’s a few that are actually free for you to have a go at and there you can actually get down into the actual code and work with code and start to understand it. If you’re actually thinking of setting up a start up then please just do a very quick sign up to NVIDIAs inception program where we can actually give you a ton of support and big discounts to hardware and of course all the software. I just want to leave you with the fact that we are hiring massively right now if you have any kind of deep learning machine learning skills or just the ninja coder please contact NVIDIA.
True Artificial Intelligence Will Change Everything
Posted on July 25th, 2018

Jürgen Schmidhuber (born 17 January 1963) is a Computer Scientist who works in the field of AI. He is a co-director of the Dalle Molle Institute for Artificial Intelligence Research in Manno, in the district of Lugano, in Ticino in southern Switzerland.Schmidhuber did his undergraduate studies at the Technische Universität München in Munich, Germany. He taught there from 2004 until 2009 when he became a professor of artificial intelligence at the Università della Svizzera Italiana in Lugano, Switzerland.
When I was a boy I wanted to maximize my impact on the world. I was smart enough to realize that I am NOT very smart. That I have to build a machine that learns to become much smarter than myself, such that it can solve all the problems that I cannot solve myself. Then I can retire and my first publication on that dates back 30 years. My 1987 diploma thesis where I already try to solve the grand problem of AI not only build a machine that learns a little bit here and there but also learns to improve the learning algorithm itself. The way it learns, recursively without any limits except the limits of logic and physics.




I’m still working on the same old thing and I’m still pretty much saying the same thing except that now more people are listening. The learning algorithms that we have developed on the way to this goal are now on three thousand million smartphones and all of you have them in your pockets. What you see here are the five most valuable companies of the Western world Apple Google Facebook Microsoft and Amazon and all of them are emphasizing that AI artificial intelligence is central to what they are doing. All of them are using heavily the deep learning methods that my team has developed since the early nineties.




Have you ever heard of the long short-term memory?
The LSTM is a little bit like your brain it’s an artificial neural network which also has neurons. In your brain you’ve got about 100 billion neurons and each of them is connected to roughly 10,000 other neurons on average which means that you have got a million billion connections. Each of these connections has a strength which says how much does this neuron over here influence that neuron over there at the next time step. In the beginning all these connections are random and the system knows nothing within. Through a smart learning algorithm it learns from lots of examples to translate the incoming data such as video through the cameras or audio through the microphones or pain signals through the pain sensors. It learns to translate that into output actions because some of these neurons are output neurons that control speech muscles and finger muscles and, through experience only, it can learn to solve all kinds of interesting problems.





Problems such as driving a car or to do the speech recognition on your smartphone, because whenever you take out your smartphone an Android phone for example, and you speak to it and you say ok Google show me the shortest way to Milano then it understands your speech because there is an LSTM in there which has learned to understand speech. Every 10 milliseconds, 100 times a second, new inputs are coming from the microphone and then translates it, after thinking, into letters which is then sent as a question to the search engine.





The basic LSTM cell looks like this.
By listening to lots of speech since 2015 Google speech recognition is now much better than it used to be.
I can list the names of the brilliant students in my lab who made that possible and what are the big companies doing with that speech recognition. As an example if you are on Facebook, I use click at the translate button because somebody sent something in a foreign language and then you can translate it. When you do that you are waking up a long short term memory and LSTM which has learned to translate text in one language into translated text and Facebook is doing that four billion times a day. Every second, 50,000 sentences are being translated by an LSTM working for Facebook and another 50,000 in the second and another 50,000 so see how much this thing is now permitting in the modern world.




Just note that almost 30 percent of the awesome computational power of all these Google Data Centers all over the world is used for LSTM. If you have an Amazon echo you can ask it questions it answers you and the voice that you hear it’s not a recording it’s an LSTM network which has learned from training examples to sound like a female voice. If you have an iPhone and you’re using quick type it’s trying to predict what you want to do next given the previous context of what you did so far. Again that’s an LSTM which has to do that so it’s on a billion iPhones.




When we started this work decades ago in the early 90s only a few people were interested because computers were so slow and you couldn’t do so much with them. I remember I gave a talk at a conference and there was just one single person in the audience a young lady. I said young lady it’s very embarrassing but apparently today I’m going to give this talk just to you and she said okay but please hurry I am the next speaker. Since then we have greatly profited from the fact that every five years computers are ten times cheaper. This is an old trend that has held since 1941 at least since this man Conrad Susan built the first working program control computer in Berlin. He could could do roughly one operation per second one and then ten years later for the same price one could do 100 operations. 30 years later 1 million operations were the same price and today after 75 years we can do a million billion times as much for the same price. The trend is not about to stop because the physical limits are much further out there. Rather soon and not so many years or decades away we will for the first time have little computational devices that can compute as much as a human brain. 50 years later there will be a little computational device for the same price that can compute as much as all 10 billion human brains taken together and there will not only be one of those devices but very many.




Everything is going to change. In 2011 computers were fast enough such that our deep learning methods for the first time could achieve a superhuman pattern-recognition result. The first superhuman result in the history of computer vision. Back then computers were 20 times more expensive than today. Today for the same price we can do 20 times as much and just five years ago when computers were 10 times more expensive than today we already could win for the first time medical imaging competitions. What you see above is a slice through the female breast and the tissue that you see there has all kinds of cells and normally you need a trained doctor a trained who is able to detect the dangerous cancer cells or pre-cancer cells. Now our stupid network knows nothing about cancer, knows nothing about vision, it knows nothing in the beginning but we can train it to imitate the human teacher. It became as good as or better than the best competitors and very soon all of medical diagnosis is going to be superhuman. It’s going to be mandatory because it’s going to be so much better than the doctors. After this all kinds of medical imaging startups were founded focusing just on this because it’s so important.




We can also use LSTM to train robots. One important thing I want to say is that we not only have systems that slavishly imitate what humans show them. We also have AI’s that set themselves their own goals and like little babies invent their own experiment to explore the world and to figure out what you can do in the world without a teacher. Becoming more and more general problem solvers in the process by learning new skills on top of old skills. This is going to scale well. Learning to invent like a scientist. I think in not so many years from now for the first time we are going to have an animal like AI. You don’t have that yet. On the level of a little monkey and once we have that it may take just a few decades to do the final step towards human level intelligence. Technological evolution is about a million times faster than biological evolution and biological evolution needed 3.5 billion years to evolve a monkey from scratch but then just a few tens of millions of years afterwards to evolve human level intelligence.




We have a company which is trying to make this a reality and build the first true general and purpose AI. At the moment almost all research in AI is very human centric and it’s all about making human lives longer and healthier and easier and making humans more addicted to their smartphones. In the long run AI’s, especially the smart ones, are going to set themselves their own goals and I have no doubt in my mind that they are going to become much smarter than we are. They are going to realize what we have realized a long time ago namely that most of the resources in the solar system or in general are not in our little biosphere. They are out there in space and so of course they are going to emigrate and of course they are going to use trillions of self-replicating robot factories to expand in form of growing AI bubble which within a few hundred thousand years is going to cover the entire galaxy.




What we are witnessing now is much more than just another Industrial Revolution this is something that transcends humankind and even life itself. The last time something so important has happened was maybe 3.5 billion years ago when life was invented. A new type of life is going to emerge from our little planet and it’s going to colonize and transform the entire universe. The universe is still young it’s only 13.8 billion years old. It’s going to become much older than that. Many times older than that. So there’s plenty of time to reach all of it or all of the visible parts totally within the limits of light speed and physics. A new type of life is going to make the universe intelligent. Now of course we are not going to remain the crown of creation, of course not, but there is still beauty in seeing yourself as part of a grander process that leads the cosmos from low complexity towards higher complexity. It’s a privilege to live at a time where we can witness the beginnings of that and where we can contribute something to that.



