




Top libraries for Distributed Deep Learning
Posted on September 21st, 2018
 Posted by Packt Publishing on June 13, 2018 at 12:30am
Posted by Packt Publishing on June 13, 2018 at 12:30amThe performance of the neural network improves with an increasing volume of training data. With more and more devices generating data that can potentially be used for training and model generation, the models are getting better at generalizing the stochastic environment and handling complex tasks. However, with more data and more complex structures for the deep neural networks, the computational requirements increase.
Even though we have started leveraging GPUs for deep neural network training, the vertical scaling of the compute infrastructure has its own limitations and cost implications. Leaving the cost implications aside, the time it takes to train a significantly large deep neural network on a large set of training data is not reasonable. However, due to the nature and network topology of the neural networks, it is possible to distribute the computation on multiple machines at the same time and merge the results back with a centralized process. This is very similar to Hadoop, as a distributed computing batch processing engine, and Spark, as an in-memory distributed computing framework.
With deep neural networks, there are two approaches for leveraging distributed computing:
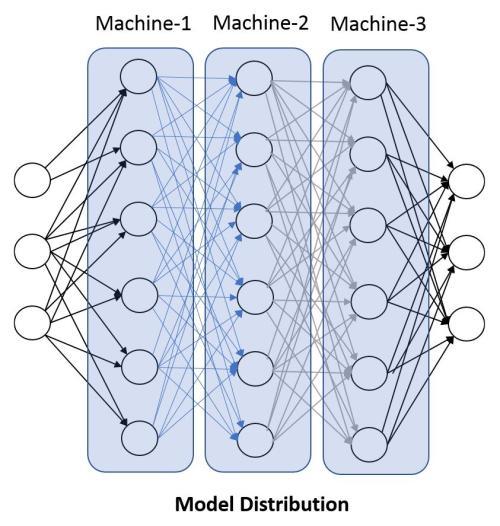
- Model Distribution: In this approach, the deep neural network is broken into logical fragments that are treated as independent models from a computational perspective. The results from these models are combined by a central process, as depicted in this diagram:
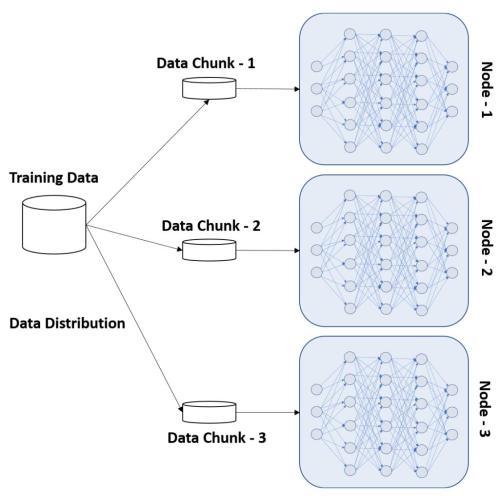
- Data Distribution: In this approach, the entire model is copied to all the nodes participating in the cluster and the data is distributed in chunks for processing. The master process collects the output from the individual nodes and produces the final outcome, shown as follows:
The data distribution approach is very similar to Hadoop’s MapReduce framework. The MapReduce job creates the input splits based on predefined and run-time configuration parameters. These chunks are sent to the independent nodes for processing by the map tasks in a parallel manner.
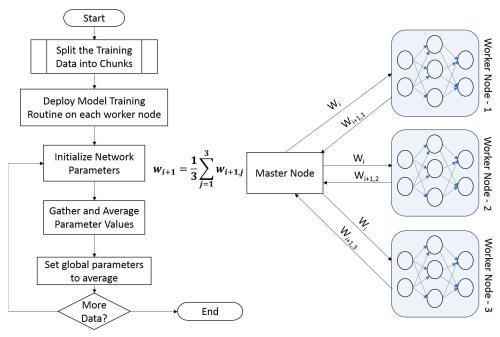
The output from the map tasks is shuffled for relevance (simple sort) and is given as input to the reduce tasks for generating intermediate results. The individual MapReduce chunks are combined to produce the final result. The data distribution approach is more naturally suitable for Hadoop and Spark frameworks and it is a more widely researched approach at this time. The deep neural networks that leverage data distribution primarily deploy a parameter-averaging strategy for training the model.
This is a simple but efficient approach for training a deep neural network with data distribution:
Based on these fundamental concepts of distributed processing, let’s review some of the popular libraries and frameworks that enable parallelized deep neural networks.
Distributed deep learning
With an ever-increasing number of data sources and data volumes, it is imperative that the deep learning application and research leverage the power of distributed computing frameworks. In this section, we will review some of the libraries and frameworks that effectively leverage distributed computing. These are popular frameworks based on their capabilities, adoption level, and active community support.
DL4J and Spark
The core framework of DL4J is designed to work seamlessly with Hadoop (HDFS and MapReduce) as well as Spark-based processing. It is easy to integrate DL4J with Spark. DL4J with Spark leverages data parallelism by sharding large datasets into manageable chunks and training the deep neural networks on each individual node in parallel. Once the models produce parameter values (weights and biases), those are iteratively averaged for producing the final outcome.
API overview
In order to train the deep neural networks on Spark using DL4J, two primary wrapper classes need to be used:
- SparkDl4jMultiLayer: A wrapper around DL4J’s MultiLayerNetwork
- SparkComputationGraph: A wrapper around DL4J’s ComputationGraph
The network configuration process for the standard, as well as the distributed, mode remains same. That means we configure the network properties by creating a MultiLayerConfiguration instance. The workflow for deep learning on Spark with DL4J can be depicted as follows:
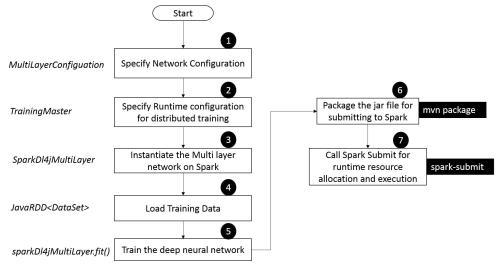
Here are the sample code snippets for the workflow steps:
- Multilayer network configuration:
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).iterations(1)
.learningRate(0.1)
.updater(Updater.RMSPROP) //To configure: .updater(new RmsProp(0.95))
.seed(12345)
.regularization(true).l2(0.001)
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new GravesLSTM.Builder().nIn(nIn).nOut(lstmLayerSize).activation(Activation.TANH).build())
.layer(1, new GravesLSTM.Builder().nIn(lstmLayerSize).nOut(lstmLayerSize).activation(Activation.TANH).build())
.layer(2, new RnnOutputLayer.Builder(LossFunctions.LossFunction.MCXENT).activation(Activation.SOFTMAX) //MCXENT + softmax for classification
.nIn(lstmLayerSize).nOut(nOut).build())
.backpropType(BackpropType.TruncatedBPTT).tBPTTForwardLength(tbpttLength).tBPTTBackwardLength(tbpttLength)
.pretrain(false).backprop(true)
.build();
- Set up the runtime configuration for the distributed training:
ParameterAveragingTrainingMaster tm = new ParameterAveragingTrainingMaster.Builder(examplesPerDataSetObject)
.workerPrefetchNumBatches(2) //Async prefetch 2 batches for each worker
.averagingFrequency(averagingFrequency)
.batchSizePerWorker(examplesPerWorker)
.build();
- Instantiate the Multilayer network on Spark with TrainingMaster:
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(sc, config, tm);
- Load the shardable training data:
public static JavaRDD<DataSet> getTrainingData(JavaSparkContext sc) throws IOException {
List<String> list = getTrainingDatAsList(); // arbitrary sample method
JavaRDD<String> rawStrings = sc.parallelize(list);
Broadcast<Map<Character, Integer>> bcCharToInt = sc.broadcast(CHAR_TO_INT);
return rawStrings.map(new StringToDataSetFn(bcCharToInt));
}
- Train the deep neural network:
sparkNetwork.fit(trainingData);
- Package the Spark application as a .jar file:
mvn package
- Submit the application to Spark runtime:
spark-submit –class fully qualified class name>> –num-executors 3 ./jar_name>>-1.0-SNAPSHOT.jar
The DeepLearning4j official website provides extensive documentation for running the deep neural networks on Spark: https://deeplearning4j.org/spark
TensorFlow
TensorFlow is the most popular library created and open sourced by Google. It uses data-flow graphs for numerical computations and deals with Tensor as the basic building block. A Tensor can simply be considered as an n-dimensional matrix. TensorFlow applications can be seamlessly deployed across platforms and it can run on GPUs and CPUs, along with mobile and embedded devices. TensorFlow is designed as a large-scale distributed training that supports new machine learning models, research, and granular-level optimizations.
TensorFlow is quick to install and start experimenting with. The latest version of TensorFlow can be downloaded from https://www.tensorflow.org/. The site also contains extensive documentation and tutorials.
Further reading:
Distributed TensorFlow: Working with multiple GPUs and servers
Keras
Keras is a high-level neural network API, written in Python and capable of running on top of TensorFlow. For more information, refer to https://keras.io/.
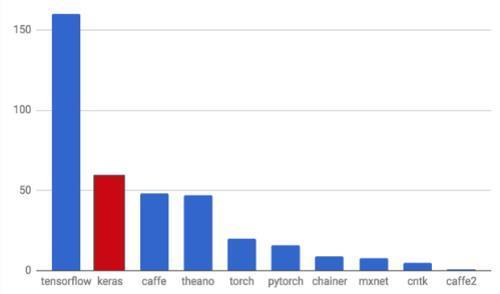
TensorFlow and Keras hold the top two spots in terms of adoption and mention by researchers in scientific papers. The stack ranking of the frameworks and libraries as per arxiv.org is as follows:
You enjoyed an excerpt from Packt Publishing’s latest book, Artificial Intelligence for Big Data written by Anand Deshpande and Manish Kumar. If you are a Java developer, this is the book you will need to build next-generation Artificial Intelligence systems.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/top-libraries-for-distributed-deep-learning.



