




Transfer Learning –Deep Learning for Everyone
Posted on October 10th, 2018

Posted by William Vorhies on April 17, 2018 at 12:25pm
View Blog
Summary: Deep Learning, based on deep neural nets is launching a thousand ventures but leaving tens of thousands behind. Transfer Learning (TL), a method of reusing previously trained deep neural nets promises to make these applications available to everyone, even those with very little labeled data.
![]()
Deep Learning, based on deep neural nets is launching a thousand ventures but leaving tens of thousands behind. The broad problems with DNNs are well known.
- Complexity leading to extended time to success and an abnormally high outright failure rate.
- Extremely large quantities of labeled data needed to train.
- Large amounts of expensive specialized compute resources.
- Scarcity of data scientist qualified to create and maintain the models.
The entire field has really come into its own only in the last two or three years and growth has been exponential among those able to overcome these drawbacks. And it’s fair to say that the deep learning provider community understands and is working to resolve these issues.
It’s likely that over the next two or three years these will be overcome. But in the meantime, large swaths of potential users are being deterred and delayed in gaining benefit.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=yofjFQddwHE[/responsive_video]
Two Main Avenues of Progress – Automation and Transfer Learning
The problem for those wanting to create their own robust multi-object classifiers is most severe. If you succeed in hiring the necessary talent, and if your pockets are deep enough for AWS, Azure, or Google cloud resources, you still face the main problems of complexity and large quantities of labeled data.
Already you can begin to find companies who claim to have solved the complexity problem by automating DNN hyperparameter tuning. Right behind these small innovators are Google and Microsoft who are publically laying out their strategies for doing the same thing.
More than any other algorithms we’ve been faced with; the hyperparameters of DNNs are the most varied and complex. Starting with the number of nodes, the number, types, and connectivity of the layers, selection of activation function, learning rate, momentum, number of epochs, and batch size for starters. The requirement for handcrafting through multiple experimental configurations is the root cause of cost, delay, and the failure of some systems to train at all.
But there is a way for companies with only modest amounts of data and modest data science resources to join the game is short order, and that’s through Transfer Learning (TL).
The Basics
![]()
TL is primarily seen today in image classification problems but has been used in video, facial recognition, and text-sequence type problems including sentiment analysis.
The central concept is to use a more complex but successful pre-trained DNN model to ‘transfer’ its learning to your more simplified (or equally but not more complex) problem.
The existing successful pre-trained model has two important attributes:
- Its tuning parameters have already been tested and found to be successful, eliminating the experimentation around setting the hyperparameters.
- The earlier or shallower layers of a CNN are essentially learning the features of the image set such as edges, shapes, textures and the like. Only the last one or two layers of a CNN are performing the most complex tasks of summarizing the vectorized image data into the classification data for the 10, 100, or 1,000 different images they are supposed to identify. These earlier shallow layers of the CNN can be thought of as featurizers, discovering the previously undefined features on which the later classification is based.
There are two fundamentally different approaches to TL, each based separately on these two attributes.
Create a Wholly New Model
If you have a fairly large amount of labeled data (estimates range down to 1,000 images per class but are probably larger) then you can utilize the more accurate TL method by creating a wholly new model using the weights and hyperparameters of the pre-trained model.
Essentially you are capitalizing on the experimentation done to make the original model successful. In training the number of layers will remain fixed (as well as the overall architecture of the model). The final layers will be optimized for your specific set of images.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=_2EHcpg52uU[/responsive_video]
Simplified Transfer Learning
The more common approach is a benefit for those with only a limited quantity of labeled data. There are some reports of being able to train with as few as 100 labeled images per class, but as always, more is better.
If you attempted to use the first technique of training the entire original model with just a few instances, you would almost surely get overfitting.
In simplified TL the pre-trained transfer model is simply chopped off at the last one or two layers. Once again, the early, shallow layers are those that have identified and vectorized the features and typically only the last one or two layers need to be replaced.
The output of the truncated ‘featurizer’ front end is then fed to a standard classifier like an SVM or logistic regression to train against your specific images.
The Promise
There’s no question that simplified TL will appeal to the larger group of disenfranchised users since it needs neither large quantities of data or exceptionally sophisticated data scientists.
It’s no surprise that the earliest offerings rolled out by Microsoft and Google focus exclusively on this technique. Other smaller providers can demonstrate both simplified and fully automated DNN techniques.
Last week we reviewed the offering from OneClick.AI that has examples of simplified TL achieving accuracies of 90% and 95%. Others have reported equally good results with limited data.
It’s also possible to use the AutoDL features from Microsoft, Google, and OneClick to create a deployable model without any code, by simply dragging-and-dropping your images onto their platform.
The Limits
Like any automated or greatly simplified data science procedure, you need to know the limits. First and foremost, the pre-trained model you choose for the starting point must process images that are similar to yours.
For example, a model trained on the extensive ImageNet database that can correctly classify thousands of objects will probably let you correctly transfer features from horses, cows, and other domestic livestock onto exotic endangered species. When doing facial recognition, best to use a different existing model like VGG.
However, trying to apply the featurization ability of an ImageNet trained DNN to more exotic data may not work well at all. Others have noted for example that medical imaging from radiography or CAT scans are originally derived in greyscale and that these image types, clearly not present in ImageNet, are unlikely to featurize accurately. Other types that should be immediately suspect might include scientific signals data or images for which there is no real world correlate, including seismic or multi-spectral images.
The underlying assumption is that the patterns in the images to be featurized existed in the pre-trained model’s training set.
The Pre-trained Model Zoo
There are a very large number of pre-trained models to use as the basis of TL. A short list drawn from the much larger universe would include:
- LeNet
- AlexNet
- OverFeat
- VGG
- GoogLeNet
- PReLUnet
- ResNet
- ImageNet
- MS Coco
All of which have several versions with different original image sets for you to pick from.
One Other Interesting Application of Transfer Learning
This may not have much commercial application but it’s interesting to know that you can use TL to combine two separate pre-trained models to achieve unexpected artistic results.
 Right now these are being applied experimentally for mostly artistic results. The technique takes one model selected for content and another model selected for style, and combines them.
Right now these are being applied experimentally for mostly artistic results. The technique takes one model selected for content and another model selected for style, and combines them.
What takes a bit of experimentation is looking at each convolutional and pooling layer to decide which unique look you want your resulting image to have.
In the End
You can go-it-alone in Tensorflow or the other DL platforms, or you can start by experimenting with one of the fully automated ADL offerings above. Neither data nor experience should hold you back from adding deep learning features to your customer-facing or internal systems.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/transfer-learning-deep-learning-for-everyone.
Goodbye Age of Hadoop – Hello Cambrian Explosion of Deep Learning
Posted on October 1st, 2018

Posted by William Vorhies on March 20, 2017 at 4:48pm
View Blog
Summary: Some observations about new major trends and directions in data science drawn from the Strata+Hadoop conference in San Jose last week.
 I’m fresh off my annual field trip to the Strata+Hadoop conference in San Jose last week. This is always exciting, enervating, and exhausting but it remains the single best place to pick up on what’s changing in our profession.
I’m fresh off my annual field trip to the Strata+Hadoop conference in San Jose last week. This is always exciting, enervating, and exhausting but it remains the single best place to pick up on what’s changing in our profession.
This conference is on a world tour with four more stops before repeating next year. The New York show is supposed to be a little bigger (hard to imagine) but the San Jose show is closest to our intellectual birthplace. After all this is the place where to call yourself a nerd would be regarded as a humble brag.
I’ll try to briefly share the major themes and changes I found this year and will write later in more depth about some of these.
End of the Era of Hadoop
From the time it went open source in 2007 Hadoop and its related technologies have been profound drivers of the growth of data science. Doug Cutting remains one of the three Strata conference chairs. However, we all know that Hadoop/MapReduce has made its mark but that it’s no longer cutting edge. In fact we know that Apache Spark has eclipsed Hadoop and it would be fair to say that Spark was last year’s big news.
To put a stake in it, O’Reilly announced at this year’s Strata+Hadoop that the conference would henceforth be known as the Strata Data Conference. So farewell age of Hadoop.
Artificial Intelligence
I am as jaded as the next guy and maybe a little more so at the over hyped furor around AI. As I walked the conference floor I felt compelled to challenge any vendor with the temerity to put AI in their descriptors.
Actually there was very little of this at the show. AI tends to be most over hyped when we’re talking about apps but Strata+Hadoop is more about tools than apps. There were two or three vendors that I thought had applied the AI frosting a little thick but there were a few others where the label was appropriate and the capabilities pretty interesting. More about these good guys later.
In the learning program there were again two or three sessions aimed at AI use cases in business and these were uniformly well reasoned. Specifically that means acknowledging that this is in its infancy and while you should keep an eye on it, investing now would be speculative at best.
The Cambrian Explosion in Deep Learning
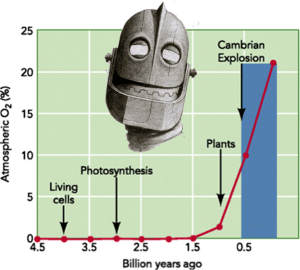 One of our general session speakers used this phrase to describe the hockey-stick like growth we’ve been experiencing in Deep Learning and AI in general. The original use of the phrase is credited to Gill Pratt, the DARPA Program Manager who oversaw the DARPA Robotics Challenge.
One of our general session speakers used this phrase to describe the hockey-stick like growth we’ve been experiencing in Deep Learning and AI in general. The original use of the phrase is credited to Gill Pratt, the DARPA Program Manager who oversaw the DARPA Robotics Challenge.
If you remember a little about your earth history, we trundled along with one-celled creatures for billions of years until about a half-a-billion years ago when, at the beginning of the Cambrian period, life diversified in a way that can truly be characterized as an explosion. Academic theory is that very small changes like the evolution of sight organs so changed the playing field that the exploitation of this new capability drove the development of additional capabilities that – you know – resulted in us.
So while data scientists are a little cautious to talk about the wonders of artificial intelligence, they are very enthusiastic in talking about the new capabilities presented by Deep Learning. This may seem a little paradoxical but I invite you to think about it this way.
Robust AI is the accumulated capabilities of speech, text, NLP, image processing, robotics, knowledge recovery, and several other human-like capabilities that at this point are very early in development and not at all well or easily integrated.
Deep Learning however is a group of tools that we are applying to develop these capabilities, including Convolutional Neural Nets, Recurrent Neural Nets, Generative Adversarial Neural Nets, and Reinforcement Learning to name the most popular. All of these are subsets of Deep Learning and all are accessed through the newly emerging Deep Learning platforms like TensorFlow, MXNet, Theano, Torch, and several others.
Like all platform battles, the winner who gains the most users will be the next IoS, Android, or Windows. Right now it appears Google’s TensorFlow is in the lead and there were at least four or five program sessions, some of them full-day, that were oversubscribed providing both general guidance as well as hands-on training in TensorFlow. So while the buzz around AI was appropriately subdued, the enthusiasm for learning about TensorFlow was in full flower. The emergence of Deep Learning platforms may be the slight evolutionary change that triggers the explosion of AI.
Platform Convergence
In the beginning you could pick a portion of the data science workflow and build a successful business there. Many of today’s largest companies got their start this way. Not anymore. Now everybody wants to be an end-to-end platform from data source to the deployment of models and other forms of exploitation. He with the most users will win and once adopted the pain of switching will be high. The same dynamic that continues to make enterprise ERP systems so sticky – it’s too painful to switch.
We’ve seen in the last years analytic platforms like SAS and SPSS add full data access and blending capability. We’ve seen blending platforms like Alteryx extend into analytics and visualization. So here are two new and rather unexpected additions to the full spectrum platform game:
Cloudera announces its own Data Science Workbench with capabilities in R, Python, and Scala.
Intel (yes Intel?) who just paid $15 Billion for Mobileye to seize its place in the self-driving car space is rolling out two data science platforms, Saffron and Nirvana, one aimed at IoT and the other at deep learning.
DataOps and Data Engineers
As recently as a year or so ago the term ‘data scientist’ applied to someone doing predictive analytics as well as the person you would turn to to implement Spark or a data lake. Thankfully over not too long a period we have come to differentiate Data Scientists from Data Engineers and acknowledge their special skill set that blends traditional CS skills with the new disciplines needed to store, extract, and utilize data for data scientists.
Now that this differentiation is a little clearer, we see a parallel rise in a new category of tools and platforms best described as DataOps. Philosophically similar to DevOps, DataOps tools and platforms are aimed at regularizing and simplifying the tasks of Data Engineers, particularly as it applies to repetitive tasks that may need to be repeated dozens or even hundreds of times for different data sources and different data destinations. Two new companies, both startups, Nexla, and Data Kitchen take a fairly narrow but deep view. Others like Qubole are laying claim to this area by better defining capabilities within their existing platforms.
Emerging Productivity Enhancements for Data Scientists
 We may think the business world is populated by companies with just a few (if any) data scientists working together and for the most part we’d be right. However, this is not the market most vendors at Strata are interested in. They are pursuing wallet share among the Global 8000. That’s 8000 companies with more than $1 Billion in revenue and assuredly 100% commitment to predictive analytics.
We may think the business world is populated by companies with just a few (if any) data scientists working together and for the most part we’d be right. However, this is not the market most vendors at Strata are interested in. They are pursuing wallet share among the Global 8000. That’s 8000 companies with more than $1 Billion in revenue and assuredly 100% commitment to predictive analytics.
I haven’t seen any specific data but an informal poll of vendors says these companies employee from 20 to several hundred data scientists each. When you have that many data scientists in one place you have to start thinking about efficiency and productivity. And there’s a major theme for this year – productivity enhancements for data scientists.
The list of vendors with this focus is too long for this article and DataOps just above is part of this. Here are just a few mentions of notable companies and their approach.
DataRobot: We reviewed DataRobot a year ago when it looked like predictive analytics was about to be fully automated and data scientists unemployed by 2025. That was a little premature. However, DataRobot has found a foothold by dramatically speeding up model development. This is one-click-to-model. Their platform cleans data, does feature engineering and identification, runs thousands of potential models/hyper parameter combinations in parallel, and deploys champion models in a fraction of the time it would take a team of data scientists.
SqlStream: Deploy a blazing fast stream processing system in a fraction of the time and with a fraction of the compute resources distros like Spark require. Make it so easy to manage that very little is needed of data engineers, and make it easy to change the logic and models within the stream without a team of data scientists.
Bansai: TensorFlow is complex and tough to learn. Bansai is introducing a higher level language that looks a lot like Python but manipulates deep learning algorithms in all the major deep learning platforms. Their initial target is reinforcement learning for robotics and the payoff is to solve the shortage of deep learning-qualified data scientists that are a bottleneck for development.
Qubole: Makes it easy to almost instantly establish a big data repository and begin analytics. You can’t completely replace data engineers but you can dramatically increase the number of data scientists each engineer can support with this SaaS implementation.
Emergence of the Data Science Appliance
 Similar to productivity enhancements but aimed at business users who want solutions without necessarily needing to know the underlying data science are a group of offerings that intentionally hide the data science and focus on the business problem.
Similar to productivity enhancements but aimed at business users who want solutions without necessarily needing to know the underlying data science are a group of offerings that intentionally hide the data science and focus on the business problem.
Anodot: Delivers a sophisticated anomaly detection system that looks at all your streaming data and decides both what’s anomalous and what’s important. This is catching on among ecommerce vendors and digital enterprises, some of whom have reportedly thrown out their internally developed anomaly detectors in favor of Anodot’s offering.
GeoStrategies: This company uses GIS data for site location and market identification and penetration studies. Lots of sophisticated platforms can do that too but GeoStrategies goes out of its way to hide the data science in favor of a UI that’s very intuitive for their business users.
Women in Data Science
Finally, my unscientific tally was that about 20% of attendees and a slightly higher percentage of presenters were women. This may not be representative of our profession as a whole as folks who attend these conferences may have different profiles than the whole industry. Still, while we might wish this was more like 50/50 I thought participation by our female members was a reasonably strong showing.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/goodbye-age-of-hadoop-hello-cambrian-explosion-of-deep-learning.
Open Source Deep Learning Frameworks and Visual Analytics
Posted on September 29th, 2018
Deep Learning gets more and more traction. It basically focuses on one section of Machine Learning: Artificial Neural Networks. This article explains why Deep Learning is a game changer in analytics, when to use it, and how Visual Analytics allows business analysts to leverage the analytic models built by a (citizen) data scientist.
What is Deep Learning and Artificial Neural Networks?
Deep Learning is the modern buzzword for artificial neural networks, one of many concepts and algorithms in machine learning to build analytics models. A neural network works similar to what we know from a human brain: You get non-linear interactions as input and transfer them to output. Neural networks leverage continuous learning and increasing knowledge in computational nodes between input and output. A neural network is a supervised algorithm in most cases, which uses historical data sets to learn correlations to predict outputs of future events, e.g. for cross selling or fraud detection. Unsupervised neural networks can be used to find new patterns and anomalies. In some cases, it makes sense to combine supervised and unsupervised algorithms.
Neural Networks are used in research for many decades and includes various sophisticated concepts like Recurrent Neural Network (RNN), Convolutional Neural Network (CNN) or Autoencoder. However, today’s powerful and elastic computing infrastructure in combination with other technologies like graphical processing units (GPU) with thousands of cores allows to do much more powerful computations with a much deeper number of layers. Hence the term “Deep Learning”.
The following picture from TensorFlow Playground shows an easy-to-use environment which includes various test data sets, configuration options and visualizations to learn and understand deep learning and neural networks:
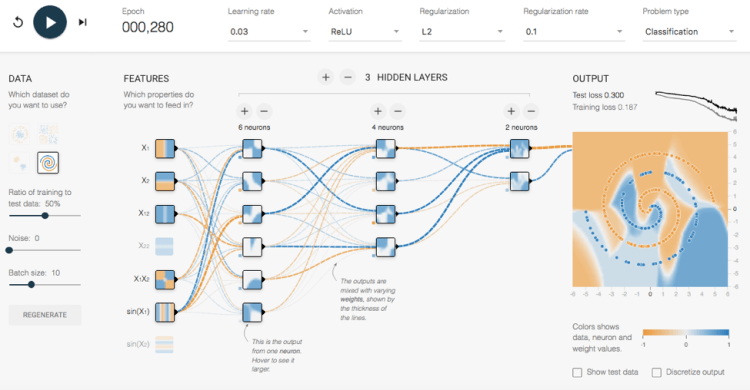
If you want to learn more about the details of Deep Learning and Neural Networks, I recommend the following sources:
- “The Anatomy of Deep Learning Frameworks”– an article about the basic concepts and components of neural networks
- TensorFlow Playground to play around with neural networks by yourself hands-on without any coding, also available on Github to build your own customized offline playground
- “Deep Learning Simplified” video series on Youtube with several short, simple explanations of basic concepts, alternative algorithms and some frameworks like H2O.ai or Tensorflow
While Deep Learning is getting more and more traction, it is not the silver bullet for every scenario.
When (not) to use Deep Learning?
Deep Learning enables many new possibilities which were not possible in “mass production” a few years ago, e.g. image classification, object recognition, speech translation or natural language processing (NLP) in much more sophisticated ways than without Deep Learning. A key benefit is the automated feature engineering, which costs a lot of time and efforts with most other machine learning alternatives.
You can also leverage Deep Learning to make better decisions, increase revenue or reduce risk for existing (“already solved”) problems instead of using other machine learning algorithms. Examples include risk calculation, fraud detection, cross selling and predictive maintenance.
However, note that Deep Learning has a few important drawbacks:
- Very expensive, i.e. slow and compute-intensive; training a deep learning model often takes days or weeks, execution also takes more time than most other algorithms.
- Hard to interpret: lack of understandability of the result of the analytic model; often a key requirement for legal or compliance regularities
- Tends to overfitting, and therefore needs regularization
Deep Learning is ideal for complex problems. It can also outperform other algorithms in moderate problems. Deep Learning should not be used for simple problems. Other algorithms like logistic regression or decision trees can solve these problems easier and faster.
Open Source Deep Learning Frameworks
Neural networks are mostly adopted using one of various open source implementations. Various mature deep learning frameworks are available for different programming languages.
The following picture shows an overview of open source deep learning frameworks and evaluates several characteristics:

These frameworks have in common that they are built for data scientists, i.e. personas with experience in programming, statistics, mathematics and machine learning. Note that writing the source code is not a big task. Typically, only a few lines of codes are needed to build an analytic model. This is completely different from other development tasks like building a web application, where you write hundreds or thousands of lines of code. In Deep Learning – and Data Science in general – it is most important to understand the concepts behind the code to build a good analytic model.
Some nice open source tools like KNIME or RapidMinerallow visual coding to speed up development and also encourage citizen data scientists (i.e. people with less experience) to learn the concepts and build deep networks. These tools use own deep learning implementations or other open source libraries like H2O.ai or DeepLearning4j as embedded framework under the hood.
If you do not want to build your own model or leverage existing pre-trained models for common deep learning tasks, you might also take a look at the offerings from the big cloud providers, e.g. AWS Polly for Text-to-Speech translation, Google Vision API for Image Content Analysis, or Microsoft’s Bot Framework to build chat bots. The tech giants have years of experience with analysing text, speech, pictures and videos and offer their experience in sophisticated analytic models as a cloud service; pay-as-you-go. You can also improve these existing models with your own data, e.g. train and improve a generic picture recognition model with pictures of your specific industry or scenario.
Deep Learning in Conjunction with Visual Analytics
No matter if you want to use “just” a framework in your favourite programming language or a visual coding tool: You need to be able to make decisions based on the built neural network. This is where visual analytics comes into play. In short, visual analytics allows any persona to make data-driven decisions instead of listening to gut feeling when analysing complex data sets. See “Using Visual Analytics for Better Decisions – An Online Guide” to understand the key benefits in more detail.
A business analyst does not understand anything about deep learning, but just leverages the integrated analytic model to answer its business questions. The analytic model is applied under the hood when the business analyst changes some parameters, features or data sets. Though, visual analytics should also be used by the (citizen) data scientist to build the neural network. See “How to Avoid the Anti-Pattern in Analytics: Three Keys for Machine …” to understand in more details how technical and non-technical people should work together using visual analytics to build neural networks, which help solving business problems. Even some parts of data preparation are best done within visual analytics tooling.
From a technical perspective, Deep Learning frameworks (and in a similar way any other Machine Learning frameworks, of course) can be integrated into visual analytics tooling in different ways. The following list includes a TIBCO Spotfire example for each alternative:
- Embedded Analytics: Implemented directly within the analytics tool (self-implementation or “OEM”); can be used by the business analyst without any knowledge about machine learning (Spotfire: Clustering via some basic, simple configuration of a input and output data plus cluster size)
- Native Integration: Connectors to directly access external deep learning clusters. (Spotfire: TERR to use R’s machine learning libraries, KNIME connector to directly integrate with external tooling)
- Framework API: Access via a Wrapper API in different programming languages. For example, you could integrate MXNet via R or TensorFlow via Python into your visual analytics tooling. This option can always be used and is appropriate if no native integration or connector is available. (Spotfire: MXNet’s R interface via Spotfire’s TERR Integration for using any R library)
- Integrated as Service via an Analytics Server: Connect external deep learning clusters indirectly via a server-side component of the analytics tool; different frameworks can be accessed by the analytics tool in a similar fashion (Spotfire: Statistics Server for external analytics tools like SAS or Matlab)
- Cloud Service: Access pre-trained models for common deep learning specific tasks like image recognition, voice recognition or text processing. Not appropriate for very specific, individual business problems of an enterprise. (Spotfire: Call public deep learning services like image recognition, speech translation, or Chat Bot from AWS, Azure, IBM, Google via REST service through Spotfire’s TERR / R interface)
All options have in common that you need to add configuration of some hyper-parameters, i.e. “high level” parameters like problem type, feature selection or regularization level. Depending on the integration option, this can be very technical and low level, or simplified and less flexible using terms which the business analyst understands.
Deep Learning Example: Autoencoder Template for TIBCO Spotfire
Let’s take one specific category of neural networks as example: Autoencoders to find anomalies. Autoencoder is an unsupervised neural network used to replicate the input dataset by restricting the number of hidden layers in a neural network. A reconstruction error is generated upon prediction. The higher the reconstruction error, the higher is the possibility of that data point being an anomaly.
Use Cases for Autoencoders include fighting financial crime, monitoring equipment sensors, healthcare claims fraud, or detecting manufacturing defects. A generic TIBCO Spotfire template is available in the TIBCO Community for free. You can simply add your data set and leverage the template to find anomalies using Autoencoders – without any complex configuration or even coding. Under the hood, the template uses H2O.ai’s deep learning implementation and its R API. It runs in a local instance on the machine where to run Spotfire. You can also take a look at the R code, but this is not needed to use the template at all and therefore optional.
Real World Example: Anomaly Detection for Predictive Maintenance
Let’s use the Autoencoder for a real-world example. In telco, you have to analyse the infrastructure continuously to find problems and issues within the network. Best before the failure happens so that you can fix it before the customer even notices the problem. Take a look at the following picture, which shows historical data of a telco network:
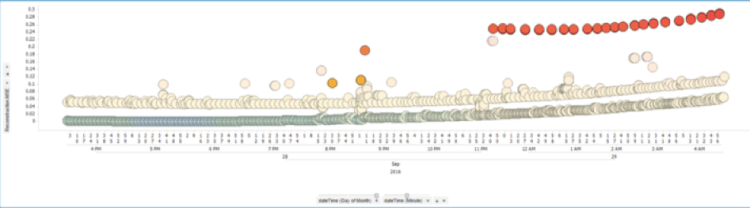
The orange dots are spikes which occur as first indication of a technical problem in the infrastructure. The red dots show a constant failure where mechanics have to replace parts of the network because it does not work anymore.
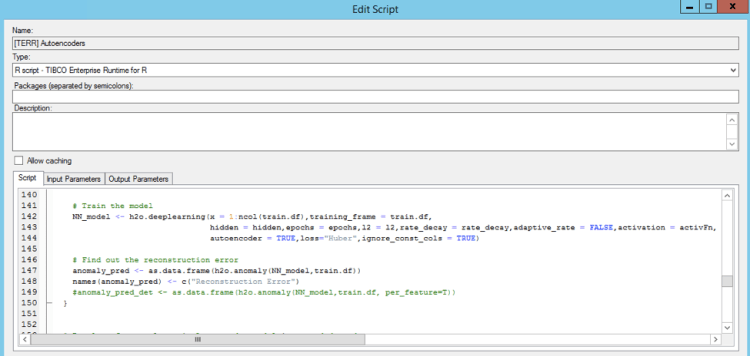
Autoencoders can be used to detect network issues before they actually happen. TIBCO Spotfire is uses H2O’s autoencoder in the background to find the anomalies. As discussed before, the source code is relative scarce. Here is the snipped of building the analytic model with H2O’s Deep Learning R API and detecting the anomalies (by finding out the reconstruction error of the Autoencoder):
This analytic model – built by the data scientist – is integrated into TIBCO Spotfire. The business analyst is able to visually analyse the historical data and the insights of the Autoencoder. This combination allows data scientists and business analysts to work together fluently. It was never easier to implement predictive maintenance and create huge business value by reducing risk and costs.
Apply Analytic Models to Real Time Processing with Streaming Analytics
This article focuses on building deep learning models with Data Science Frameworks and Visual Analytics. Key for success in projects is to apply the build analytic model to new events in real time to add business value like increasing revenue, reducing cost or reducing risk.
“How to Apply Machine Learning to Event Processing” describes in more detail how to apply analytic models to real time processing. Or watch the corresponding video recording leveraging TIBCO StreamBase to apply some H2O models in real time. Finally, I can recommend to learn about various streaming analytics frameworks to apply analytic models.
Let’s come back to the Autoencoder use case to realize predictive maintenance in telcos. In TIBCO StreamBase, you can easily apply the built H2O Autoencoder model without any redevelopment via StreamBase’ H2O connector. You just attach the Java code generated by H2O framework, which contains the analytic model and compiles to very performant JVM bytecode:
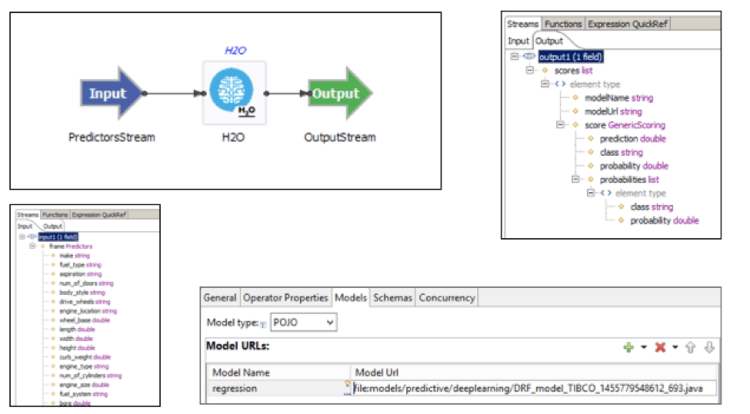
The most important lesson learned: Think about the execution requirements before building the analytic model. What performance do you need regarding latency? How many events do you need to process per minute, second or millisecond? Do you need to distribute the analytic model to a clusters with many nodes? How often do you have to improve and redeploy the analytic model? You need to answer these questions at the beginning of your project to avoid double efforts and redevelopment of analytic models!
Another important fact is that analytic models do not always need “real time processing” in terms of very fast and / or frequent model execution. In the above telco example, these spikes and failures might happen in subsequent days or even weeks. Thus, in many use cases, it is fine to apply an analytic model once a day or week instead of just every second to every new event, therefore.
Deep Learning + Visual Analytics + Streaming Analytics = Next Generation Big Data Success Stories
Deep Learning allows to solve many well understood problems like cross selling, fraud detection or predictive maintenance in a more efficient way. In addition, you can solve additional scenarios, which were not possible to solve before, like accurate and efficient object detection or speech-to-text translation.
Visual Analytics is a key component in Deep Learning projects to be successful. It eases the development of deep neural networks by (citizen) data scientists and allows business analysts to leverage these analytic models to find new insights and patterns.
Today, (citizen) data scientists use programming languages like R or Python, deep learning frameworks like Theano, TensorFlow, MXNet or H2O’s Deep Water and a visual analytics tool like TIBCO Spotfire to build deep neural networks. The analytic model is embedded into a view for the business analyst to leverage it without knowing the technology details.
In the future, visual analytics tools might embed neural network features like they already embed other machine learning features like clustering or logistic regression today. This will allow business analysts to leverage Deep Learning without the help of a data scientist and be appropriate for simpler use cases.
However, do not forget that building an analytic model to find insights is just the first part of a project. Deploying it to real time afterwards is as important as second step. Good integration between tooling for finding insights and applying insights to new events can improve time-to-market and model quality in data science projects significantly. The development lifecycle is a continuous closed loop. The analytic model needs to be validated and rebuild in certain sequences.
Content retrieved from: https://www.datavizualization.datasciencecentral.com/blog/open-source-deep-learning-frameworks-and-visual-analytics.
An Executive Primer to Deep Learning
Posted on September 23rd, 2018
 Posted by Pradeep Menon on February 20, 2018 at 4:30pm
Posted by Pradeep Menon on February 20, 2018 at 4:30pmCirca 1997, the reigning world chess champion Garry Kasparov was against an unknown opponent. The opponent was formidable. Garry was not playing a human. He was playing the game with IBM’s behemoth supercomputer, Deep Blue.
Garry had beaten the opponent in the last few games. However, the game played on 11th May 1997 game was different. Garry lost the game. Deep Blue made history:
The First computer program to defeat a world champion in a match under tournament regulations.
This game was significant for many reasons. It caught the world imagination. It laid the foundation for many possibilities that will shape the world of AI. Like explorers, data scientists and software engineers embarked on the relatively unchartered territory of Deep Learning.
Fast forward 2018, Deep Learning is a buzz word. According to Gartner, Deep Learning has already crossed the innovation trigger stage. It has reached the stage of the peak of inflated expectation.
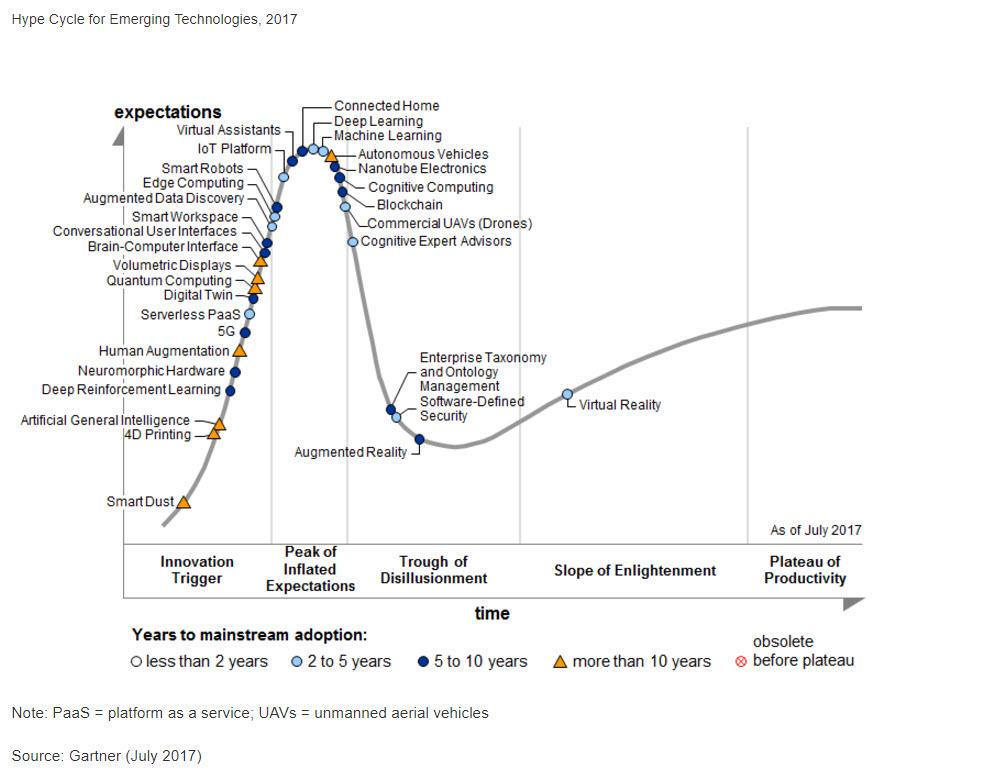
It will be another few years before this technology goes mainstream. However, the applications of deep learning have already permeated in our lives.
This article is a primer for deep learning. It attempts to provide a simple explanation of the fundamental concepts. It discusses the reason for its rise and touches upon few applications of Deep Learning.
The Concept
Let us first classify deep learning in the world of Artificial Intelligence.
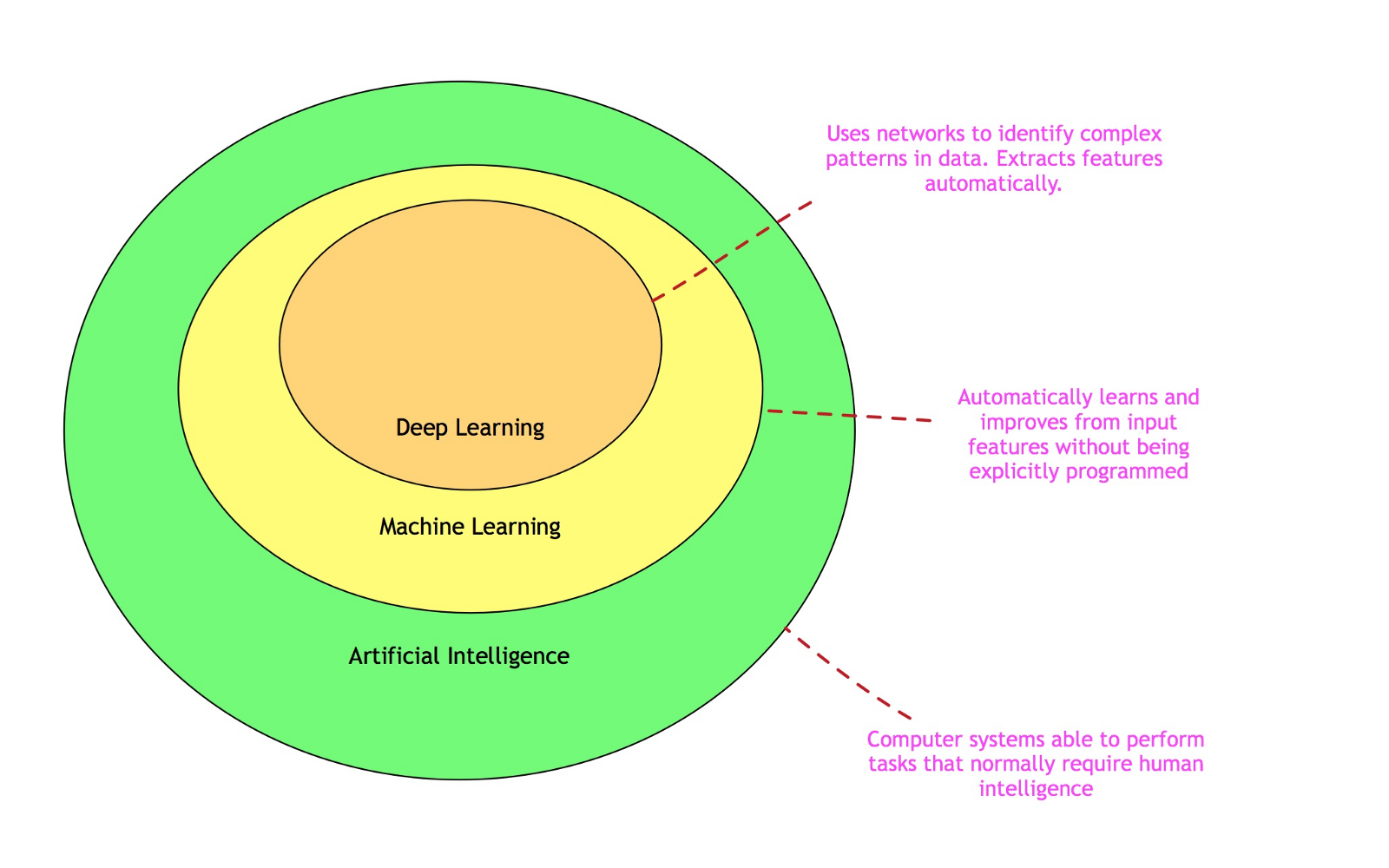
As depicted in the figure above, deep learning is a sub-set of Machine Learning. Machine Learning is in itself a subset of Artificial Intelligence (AI)AI is a field that enables machines to become intelligent progressively.
That intelligence can manifest in many ways. Let us understand how deep learning systems manifests itself.
A Rule-Based System
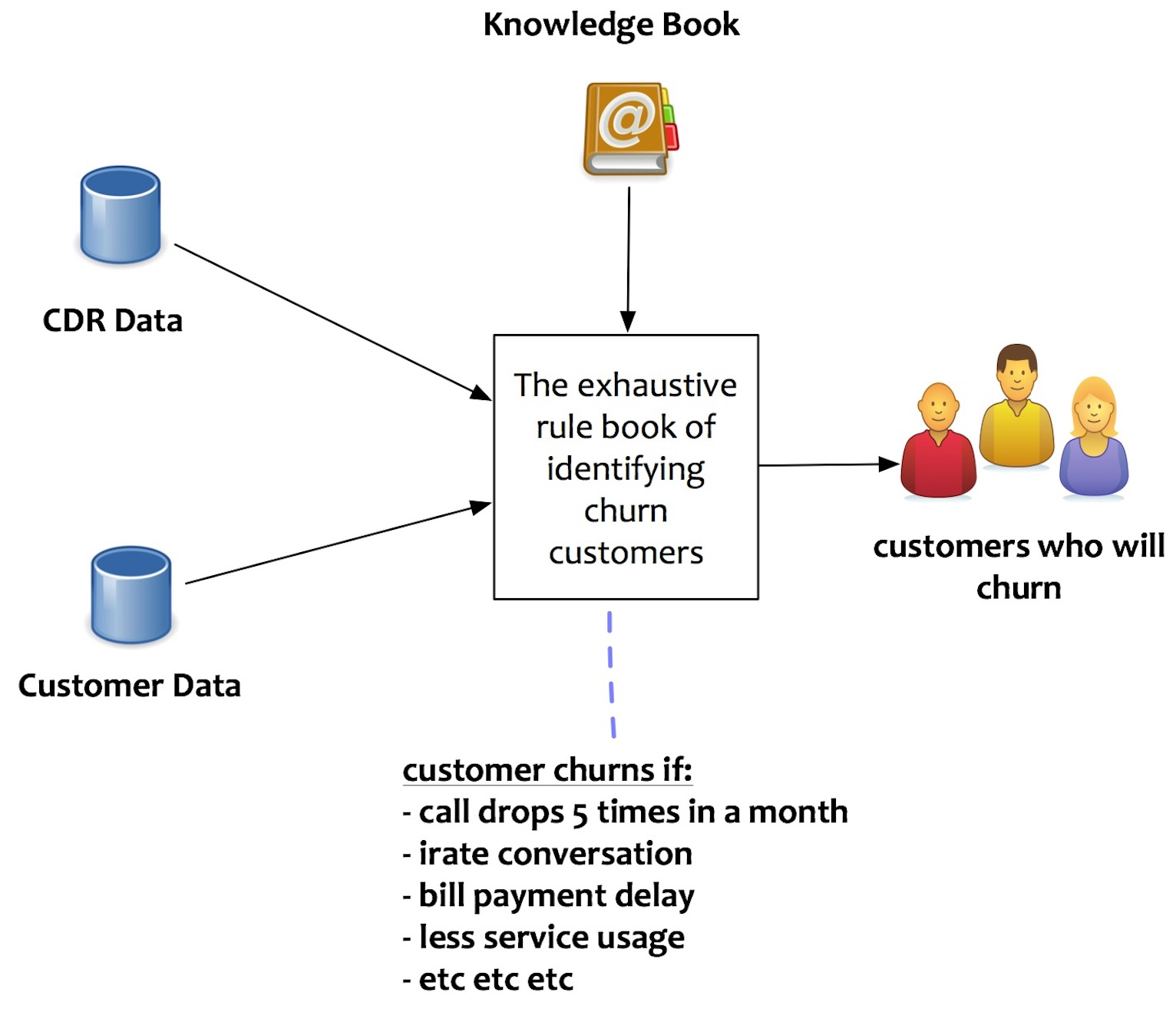
Imagine a system that enables to identify customer churn for a telco organization. One way to design this system is to craft rules about how to determine who will churn. A series of business rules are hand-crafted for a specific purpose, i.e., identify customers who will churn. Creating lot of rules is an arduous task. There are a lot of factors and their permutations. Rules are also prone to frequent changes. As the customer profile changes or the business model changes, these rules need to be altered.
This is a rudimentary form of AI. A rule-based system.
A Machine Learning System
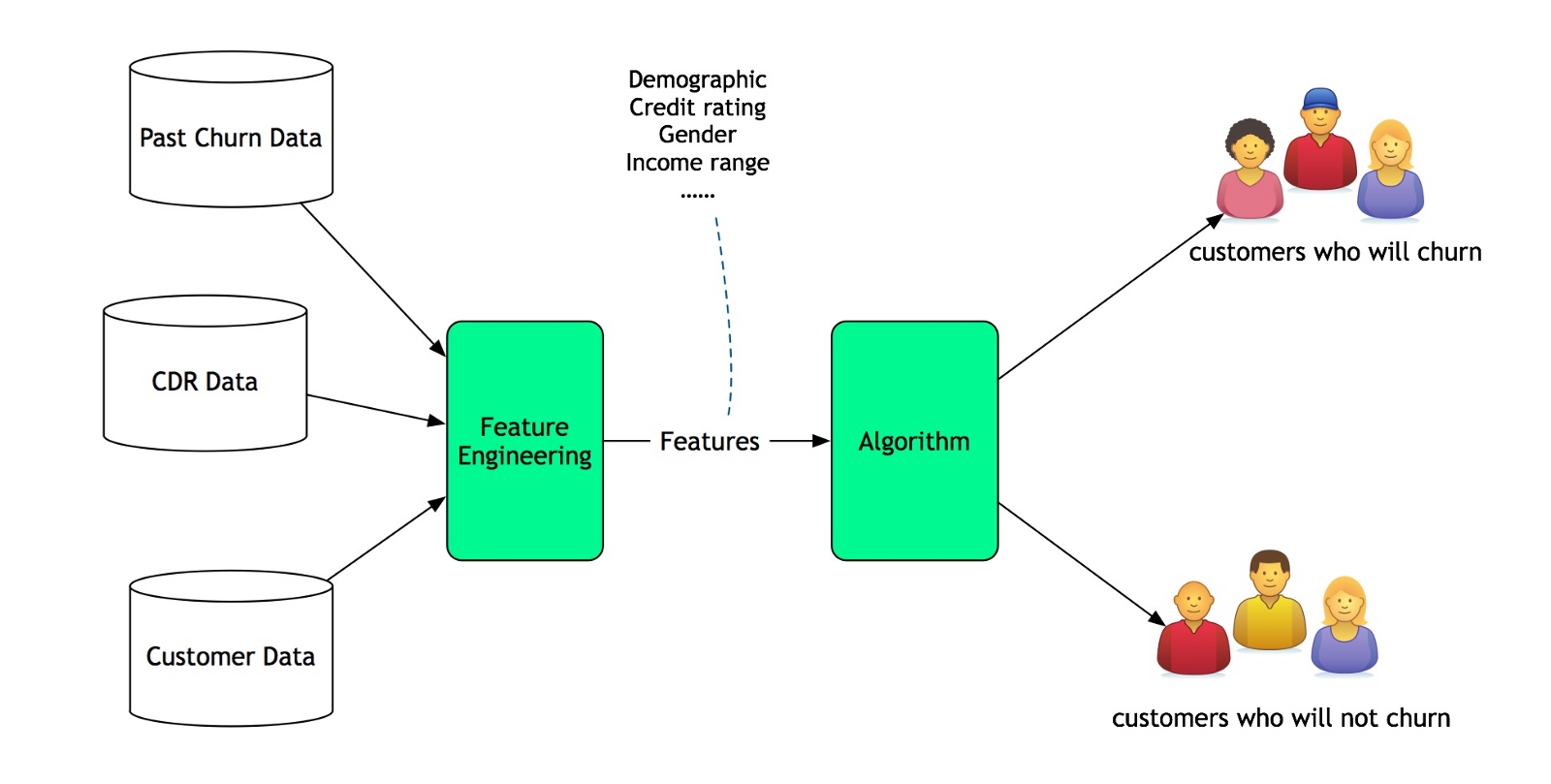
Another way to identify customer churn would create statistical learning models. They learn it from past churn information. These models take some inputs a.k.a features. These features impact customer churn. They predict if customer churns or not.
These models are Machine Learning models. They learn from the past data and input features. They adapt to the characteristics of input data changes.
Note that these machine learning models rely on humans to provide the input features. For the model to be effective, the input feature needs to be useful. They rely on the intuition and domain knowledge of the modeler. The modeler will have to feed the machine learning model with the correct features. It asks for the right representation of the data.
This is a Machine Learning based AI systems.
A Deep Learning System
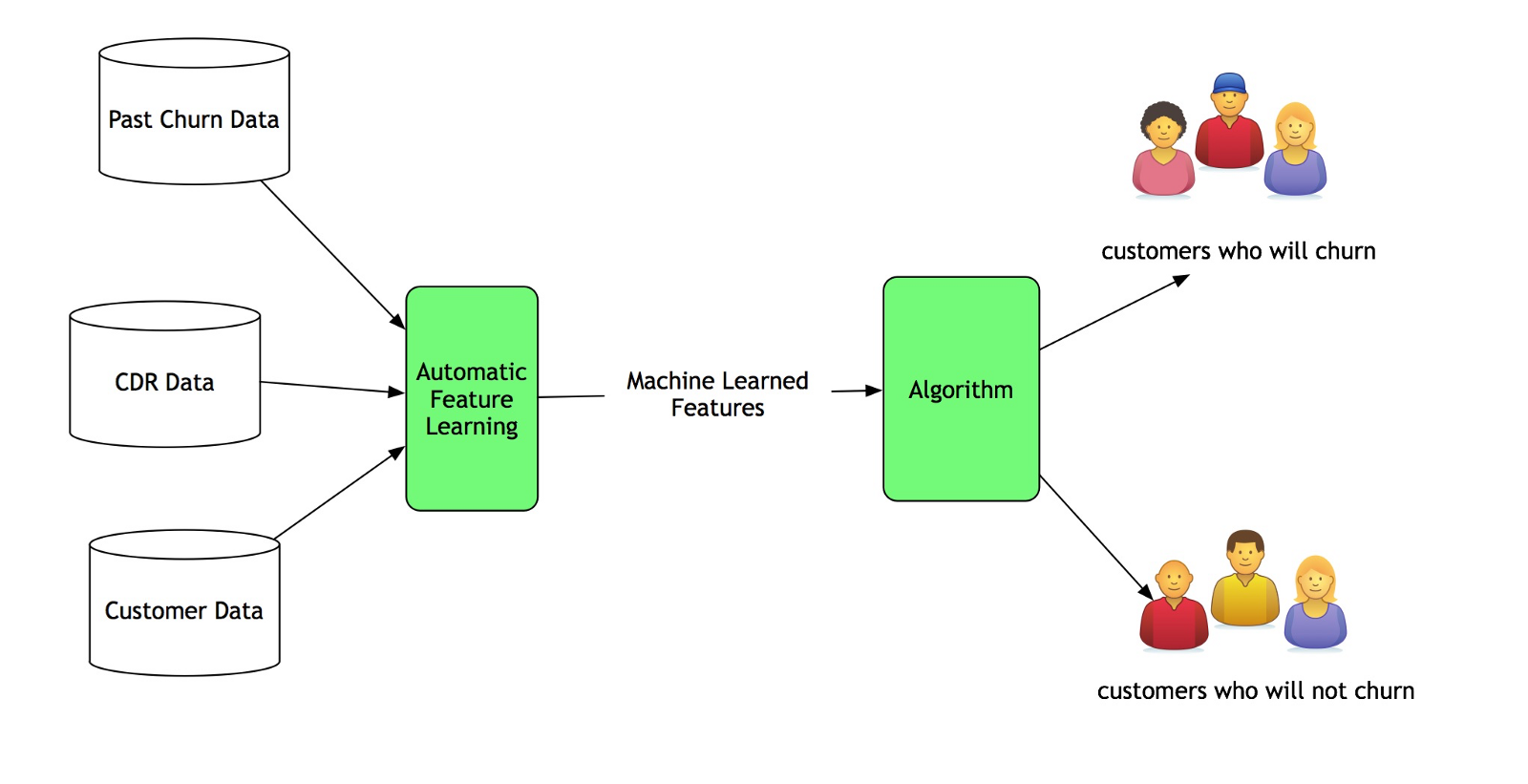
A traditional machine learning model works fine as long as the representation of the data is congruous to the expected output. However, when the number of potential features grows, identifying right input features becomes a challenge. Machine Learning practitioner also call this challenge the curse of dimensionality. In a traditional machine learning model development, a lot of time is spent on feature engineering.
In the example of customer churn, a lot more features impact customer churn. Some of these features are unknown. Some of them are derived.
What if these features can be learned automatically?
Such scenarios, where there are a lot of unknown features is where a deep learning based system shines. A deep learning based system automatically learns the relevant characteristics that cause the churn. It acquires the right representation of data.
The process of “learning the features automatically” is called as Representational Learning.
Neural Networks: The Building Block of a Deep Learning System
A deep learning based system automatically learns the relevant features to solve a machine learning task. That’s great! But how does it do it?
The building block of a deep learning network is a machine learning algorithm called neural networks.
Deep neural networks are the cornerstone algorithms that make deep learning happen. A neural net consists of a lot of simple processing interconnected nodes.
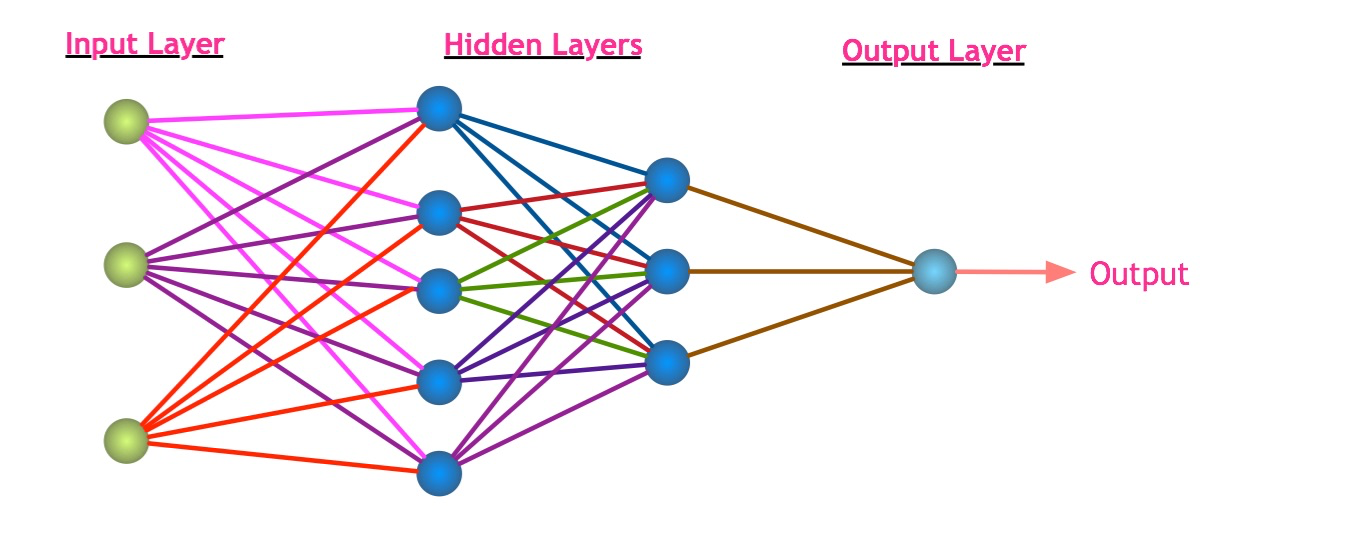
A deep neural network has three types of layers:
- – An input layer: A input or stream of data points.
- – Hidden layers: Processing nodes that are interconnected with the input. A deep neural network has more than two hidden layers.
- – An output layer: A node that transforms the processed information into usable output.
Neural networks work on a simple to complex pattern recognition. They learn simple features in the first layers of the net. Some nodes are activated based on defined thresholds. These activated nodes input into the subsequent layers of the network. In the following layers, it combines those features to derive other sophisticated features. The process goes on until it computes the final output in the output layer.
Deep Learning has been around for quite some time.
Why is deep learning becoming popular now?
The Rise of Deep Learning
In 1943, Warren McCulloch wrote a paper on neurons might work. However, in the earlier years, the progress and adoption of the neural network were impeded by two significant limitations:
- Lack of volume of data availability to train deep neural networks.
- The sheer computing power required to train deep neural networks.
With the advent of Big Data and cloud computing, these limitations were no longer an impediment.
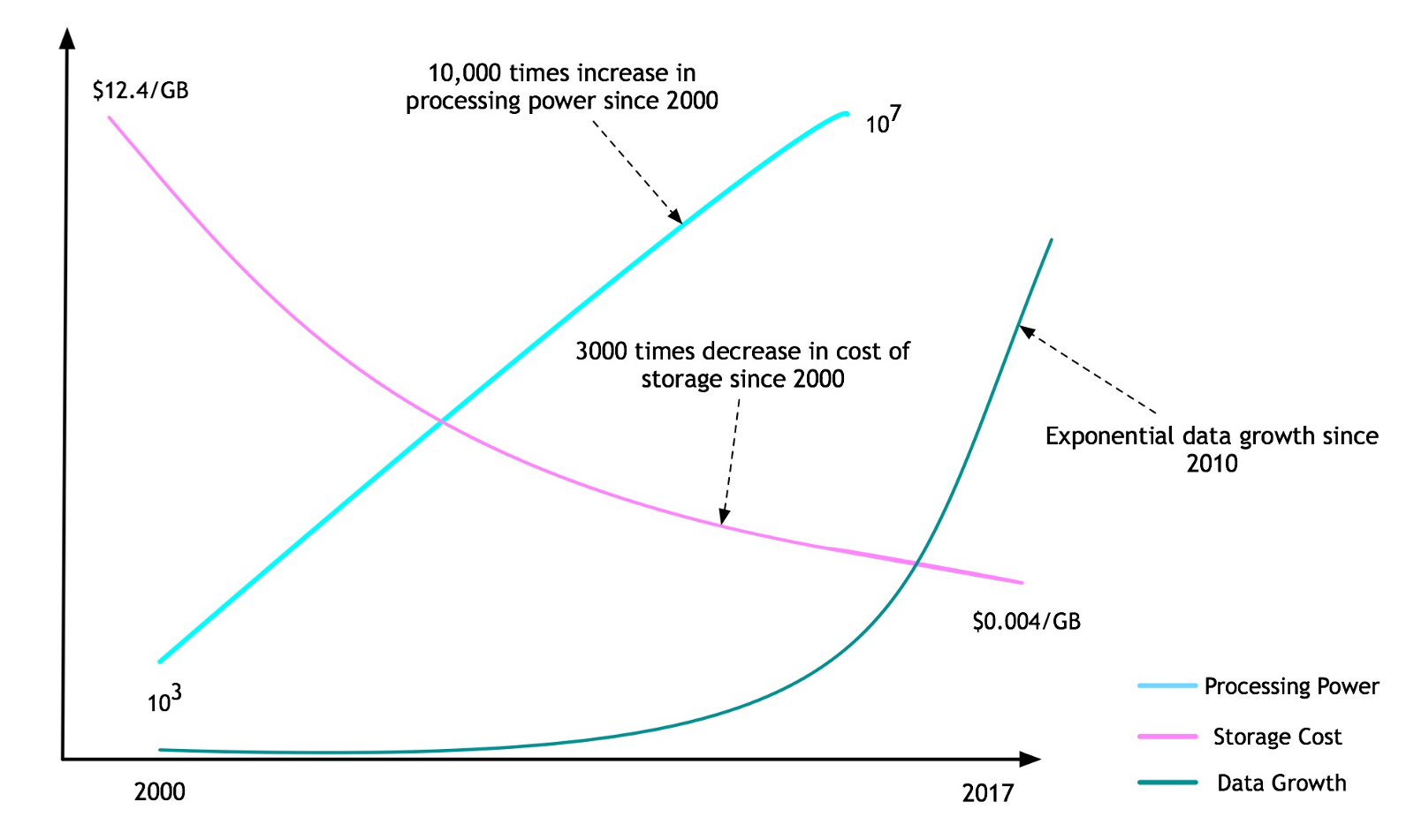
As shown in the figure above, the computing power increased by 10,000 times since the year 2000. The cost of storing the data has also gone down by around 3000 times since the year 2000. There has been an exponential growth of data created due to the rise of the internet, the smartphone revolution and the social media. Data is ubiquitously available now. These three ingredients created a milieu for a perfect storm for deep learning. Deep Learning saw a rekindled interest in research and a resurgence in adoption.
Key Applications
It turns out that deep learning frameworks are efficient to carry out tasks that humans excel at. Humans excel in tasks like image recognition, speech translation, and recognition. Humans are good at recognizing patterns in images and identify specific objects. Humans are good at processing languages, understanding them and classifying them into intents and entities. Deep Learning networks excel in these kinds of tasks too. Major domains in which deep learning is used extensively are:
Computer Vision
Computer vision is an interdisciplinary field that deals with how computers can be used for gaining understanding of images.
A few applications that use computer vision are:
– Object recognition: identifying or classifying objects in images or video streams.
– Face recognition: recognition faces in an image or video streams.
Natural Language Processing
Natural Language Processing is the application of computational techniques to the analysis and synthesis of natural language and speech
Deep Learning frameworks have managed to beat humans in speech recognition. In Jan 2018, Microsoft’s and Alibaba’s speech recognition models were able to score more than humans. It was a challenge known as SQuAD, for Stanford Question Answering Dataset.
A few applications that use speech recognition are:
- – Speech recognition: recognition of human speech.
- – Entity-Intent recognition: recognition of intents and entities in a conversation or text.
- – Speech to text/Text to speech conversion: converting a speech to text and vice versa.
Conclusion
In this article, we touched upon the core components of deep learning. We discussed why it is on the rise and what are its important applications.
Deep Learning framework is at the center of the rise of Artificial Intelligence. It is an evolving field. It will continue to see growing adoption in coming years. Deep Learning applications will continue to transform the world we live.
References:
- deeplearning.ai — Neural Networks and Deep Learning
- Explained Neural Networks
- Goodfellow, Bengio and Courville, 2016
- MGI-Artificial Intelligence: The Next Digital Frontier
- Wired: AI BEAT HUMANS AT READING! MAYBE NOT
This article was first published at www.datascientia.blog.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/an-executive-primer-to-deep-learning.
Top libraries for Distributed Deep Learning
Posted on September 21st, 2018
 Posted by Packt Publishing on June 13, 2018 at 12:30am
Posted by Packt Publishing on June 13, 2018 at 12:30amThe performance of the neural network improves with an increasing volume of training data. With more and more devices generating data that can potentially be used for training and model generation, the models are getting better at generalizing the stochastic environment and handling complex tasks. However, with more data and more complex structures for the deep neural networks, the computational requirements increase.
Even though we have started leveraging GPUs for deep neural network training, the vertical scaling of the compute infrastructure has its own limitations and cost implications. Leaving the cost implications aside, the time it takes to train a significantly large deep neural network on a large set of training data is not reasonable. However, due to the nature and network topology of the neural networks, it is possible to distribute the computation on multiple machines at the same time and merge the results back with a centralized process. This is very similar to Hadoop, as a distributed computing batch processing engine, and Spark, as an in-memory distributed computing framework.
With deep neural networks, there are two approaches for leveraging distributed computing:
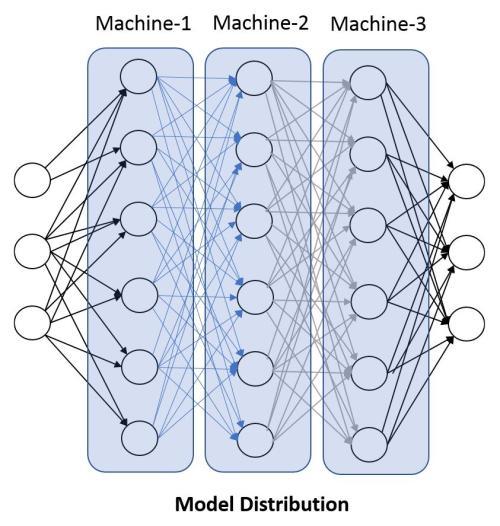
- Model Distribution: In this approach, the deep neural network is broken into logical fragments that are treated as independent models from a computational perspective. The results from these models are combined by a central process, as depicted in this diagram:
- Data Distribution: In this approach, the entire model is copied to all the nodes participating in the cluster and the data is distributed in chunks for processing. The master process collects the output from the individual nodes and produces the final outcome, shown as follows:
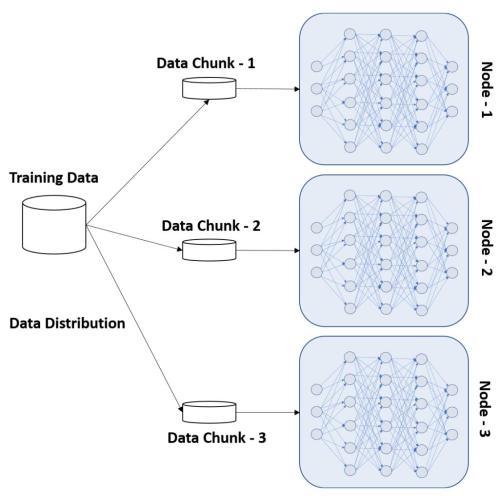
The data distribution approach is very similar to Hadoop’s MapReduce framework. The MapReduce job creates the input splits based on predefined and run-time configuration parameters. These chunks are sent to the independent nodes for processing by the map tasks in a parallel manner.
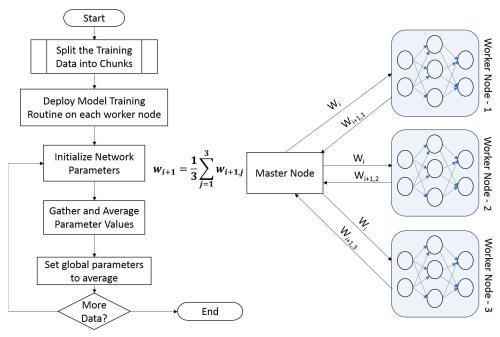
The output from the map tasks is shuffled for relevance (simple sort) and is given as input to the reduce tasks for generating intermediate results. The individual MapReduce chunks are combined to produce the final result. The data distribution approach is more naturally suitable for Hadoop and Spark frameworks and it is a more widely researched approach at this time. The deep neural networks that leverage data distribution primarily deploy a parameter-averaging strategy for training the model.
This is a simple but efficient approach for training a deep neural network with data distribution:
Based on these fundamental concepts of distributed processing, let’s review some of the popular libraries and frameworks that enable parallelized deep neural networks.
Distributed deep learning
With an ever-increasing number of data sources and data volumes, it is imperative that the deep learning application and research leverage the power of distributed computing frameworks. In this section, we will review some of the libraries and frameworks that effectively leverage distributed computing. These are popular frameworks based on their capabilities, adoption level, and active community support.
DL4J and Spark
The core framework of DL4J is designed to work seamlessly with Hadoop (HDFS and MapReduce) as well as Spark-based processing. It is easy to integrate DL4J with Spark. DL4J with Spark leverages data parallelism by sharding large datasets into manageable chunks and training the deep neural networks on each individual node in parallel. Once the models produce parameter values (weights and biases), those are iteratively averaged for producing the final outcome.
API overview
In order to train the deep neural networks on Spark using DL4J, two primary wrapper classes need to be used:
- SparkDl4jMultiLayer: A wrapper around DL4J’s MultiLayerNetwork
- SparkComputationGraph: A wrapper around DL4J’s ComputationGraph
The network configuration process for the standard, as well as the distributed, mode remains same. That means we configure the network properties by creating a MultiLayerConfiguration instance. The workflow for deep learning on Spark with DL4J can be depicted as follows:
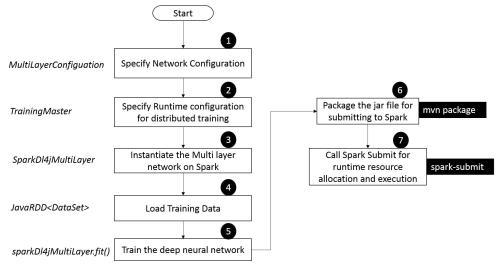
Here are the sample code snippets for the workflow steps:
- Multilayer network configuration:
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).iterations(1)
.learningRate(0.1)
.updater(Updater.RMSPROP) //To configure: .updater(new RmsProp(0.95))
.seed(12345)
.regularization(true).l2(0.001)
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new GravesLSTM.Builder().nIn(nIn).nOut(lstmLayerSize).activation(Activation.TANH).build())
.layer(1, new GravesLSTM.Builder().nIn(lstmLayerSize).nOut(lstmLayerSize).activation(Activation.TANH).build())
.layer(2, new RnnOutputLayer.Builder(LossFunctions.LossFunction.MCXENT).activation(Activation.SOFTMAX) //MCXENT + softmax for classification
.nIn(lstmLayerSize).nOut(nOut).build())
.backpropType(BackpropType.TruncatedBPTT).tBPTTForwardLength(tbpttLength).tBPTTBackwardLength(tbpttLength)
.pretrain(false).backprop(true)
.build();
- Set up the runtime configuration for the distributed training:
ParameterAveragingTrainingMaster tm = new ParameterAveragingTrainingMaster.Builder(examplesPerDataSetObject)
.workerPrefetchNumBatches(2) //Async prefetch 2 batches for each worker
.averagingFrequency(averagingFrequency)
.batchSizePerWorker(examplesPerWorker)
.build();
- Instantiate the Multilayer network on Spark with TrainingMaster:
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(sc, config, tm);
- Load the shardable training data:
public static JavaRDD<DataSet> getTrainingData(JavaSparkContext sc) throws IOException {
List<String> list = getTrainingDatAsList(); // arbitrary sample method
JavaRDD<String> rawStrings = sc.parallelize(list);
Broadcast<Map<Character, Integer>> bcCharToInt = sc.broadcast(CHAR_TO_INT);
return rawStrings.map(new StringToDataSetFn(bcCharToInt));
}
- Train the deep neural network:
sparkNetwork.fit(trainingData);
- Package the Spark application as a .jar file:
mvn package
- Submit the application to Spark runtime:
spark-submit –class fully qualified class name>> –num-executors 3 ./jar_name>>-1.0-SNAPSHOT.jar
The DeepLearning4j official website provides extensive documentation for running the deep neural networks on Spark: https://deeplearning4j.org/spark
TensorFlow
TensorFlow is the most popular library created and open sourced by Google. It uses data-flow graphs for numerical computations and deals with Tensor as the basic building block. A Tensor can simply be considered as an n-dimensional matrix. TensorFlow applications can be seamlessly deployed across platforms and it can run on GPUs and CPUs, along with mobile and embedded devices. TensorFlow is designed as a large-scale distributed training that supports new machine learning models, research, and granular-level optimizations.
TensorFlow is quick to install and start experimenting with. The latest version of TensorFlow can be downloaded from https://www.tensorflow.org/. The site also contains extensive documentation and tutorials.
Further reading:
Distributed TensorFlow: Working with multiple GPUs and servers
Keras
Keras is a high-level neural network API, written in Python and capable of running on top of TensorFlow. For more information, refer to https://keras.io/.
TensorFlow and Keras hold the top two spots in terms of adoption and mention by researchers in scientific papers. The stack ranking of the frameworks and libraries as per arxiv.org is as follows:
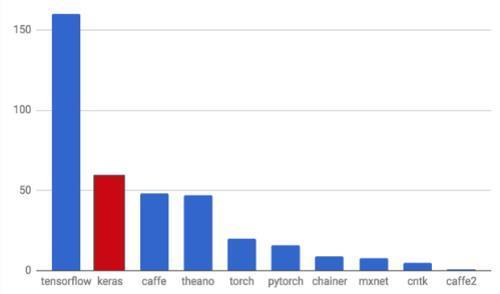
You enjoyed an excerpt from Packt Publishing’s latest book, Artificial Intelligence for Big Data written by Anand Deshpande and Manish Kumar. If you are a Java developer, this is the book you will need to build next-generation Artificial Intelligence systems.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/top-libraries-for-distributed-deep-learning.
Python Deep Learning tutorial: Create a GRU (RNN) in TensorFlow
Posted on September 17th, 2018
 Posted by Capri Granville on January 27, 2018 at 7:00pm
Posted by Capri Granville on January 27, 2018 at 7:00pmGuest blog post by Kevin Jacobs.
MLPs (Multi-Layer Perceptrons) are great for many classification and regression tasks. However, it is hard for MLPs to do classification and regression on sequences. In this Python deep learning tutorial, a GRU is implemented in TensorFlow. Tensorflow is one of the many Python Deep Learning libraries.
By the way, another great article on Machine Learning is this article on Machine Learning fraud detection. If you are interested in another article on RNNs, you should definitely read this article on the Elman RNN.
What is a GRU or RNN?
A sequence is an ordered set of items and sequences appear everywhere. In the stock market, the closing price is a sequence. Here, time is the ordering. In sentences, words follow a certain ordering. Therefore, sentences can be viewed as sequences. A gigantic MLP could learn parameters based on sequences, but this would be infeasible in terms of computation time. The family of Recurrent Neural Networks (RNNs) solve this by specifying hidden states which do not only depend on the input, but also on the previous hidden state. GRUs are one of the simplest RNNs. Vanilla RNNs are even simpler, but these models suffer from the Vanishing Gradient problem.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=dFARw8Pm0Gk[/responsive_video]
Mathematical GRU Model
The key idea of GRUs is that the gradient chains do not vanish due to the length of sequences. This is done by allowing the model to pass values completely through the cells. The model is defined as the following [1]:


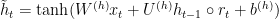

I had a hard time understanding this model, but it turns out that it is not too hard to understand. In the definitions, 
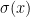
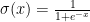
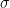

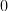
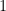

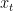
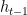
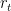
The Task: Adding Numbers
In the code example, a simple task is used for testing the GRU. Given two numbers 

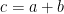
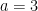

![a = [0, 1, 1]](https://s0.wp.com/latex.php?latex=a+%3D+%5B0%2C+1%2C+1%5D&bg=ffffff&fg=000000&s=0)
![b = [0, 0, 1]](https://s0.wp.com/latex.php?latex=b+%3D+%5B0%2C+0%2C+1%5D&bg=ffffff&fg=000000&s=0)
![a = [1, 1, 0]](https://s0.wp.com/latex.php?latex=a+%3D+%5B1%2C+1%2C+0%5D&bg=ffffff&fg=000000&s=0)
![b = [1, 0, 0]](https://s0.wp.com/latex.php?latex=b+%3D+%5B1%2C+0%2C+0%5D&bg=ffffff&fg=000000&s=0)
![c = [0, 0, 1]](https://s0.wp.com/latex.php?latex=c+%3D+%5B0%2C+0%2C+1%5D&bg=ffffff&fg=000000&s=0)
![[1, 0, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%2C+0%5D&bg=ffffff&fg=000000&s=0)
The Code
The code is self-explaining. If you have any questions, feel free to ask! The code can also be found on GitHub. Sharing (or Starring) is Caring :-)!
Results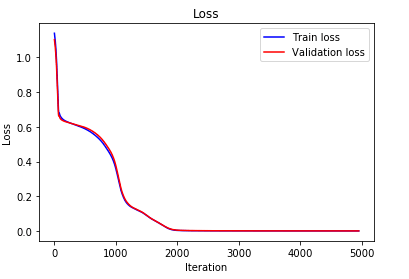
After ~2000 iterations, the model has fully learned how to add 2 integer numbers!
Conclusion (TL;DR)
This Python deep learning tutorial showed how to implement a GRU in Tensorflow. The implementation of the GRU in TensorFlow takes only ~30 lines of code! There are some issues with respect to parallelization, but these issues can be resolved using the TensorFlow API efficiently. In this tutorial, the model is capable of learning how to add two integer numbers (of any length).
To access the source code and view the original article, click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
- Difference between Machine Learning, Data Science, AI, Deep Learnin…
- What is Data Science? 24 Fundamental Articles Answering This Question
- Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Advanced Machine Learning with Basic Excel
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/gru-implementation-in-tensorflow.
Automated Deep Learning – So Simple Anyone Can Do It
Posted on September 13th, 2018

Posted by William Vorhies on April 10, 2018 at 8:18am
View Blog
Summary: There are several things holding back our use of deep learning methods and chief among them is that they are complicated and hard. Now there are three platforms that offer Automated Deep Learning (ADL) so simple that almost anyone can do it.

There are several things holding back our use of deep learning methods and chief among them is that they are complicated and hard.
A small percentage of our data science community has chosen the path of learning these new techniques, but it’s a major departure both in problem type and technique from the predictive and prescriptive modeling that makes up 90% of what we get paid to do.
Artificial intelligence, at least in the true sense of image, video, text, and speech recognition and processing is on everyone’s lips but it’s still hard to find a data scientist qualified to execute your project.
Actually when I list image, video, text, and speech applications I’m selling deep learning a little short. While these are the best known and perhaps most obvious applications, deep neural nets (DNNs) are also proving excellent at forecasting time series data, and also in complex traditional consumer propensity problems.
Last December as I was listing my predictions for 2018, I noted that Gartner had said that during 2018, DNNs would become a standard component in the toolbox of 80% of data scientists. My prediction was that while the first provider to accomplish this level of simplicity would certainly be richly rewarded, no way was it going to be 2018. It seems I was wrong.
Here we are and it’s only April and I’ve recently been introduced to three different platforms that have the goal of making deep learning so easy, anyone (well at least any data scientist) can do it.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=_2EHcpg52uU[/responsive_video]
Minimum Requirements
All of the majors and several smaller companies offer greatly simplified tools for executing CNNs or RNN/LSTMs, but these still require experimental hand tuning of the layer types and number, connectivity, nodes, and all the other hyperparameters that so often defeat initial success.
To be part of this group you need a truly one-click application that allows the average data scientists or even developer to build a successful image or text classifier.
The quickest route to this goal is by transfer learning. In DL, transfer learning means taking a previously built successful, large, complex CNN or RNN/LSTM model and using a new more limited data set to train against it.
Basically transfer learning, most used in image classification, summarizes the more complex model into fewer or previously trained categories. Transfer learning can’t create classifications that weren’t in the original model, but it can learn to create subsets or summary categories of what’s there.
The advantage is that the hyperparameter tuning has already been done so you know the model will train. More importantly, you can build a successful transfer model with just a few hundred labeled images in less than an hour.
The real holy grail of AutoDL however, is fully automated hyperparameter tuning, not transfer learning. As you’ll read below, some are on track, and others claim to already have succeeded.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=f4XBxNuEifQ[/responsive_video]
Microsoft CustomVision.AI
Late in 2017 MS introduced a series of greatly simplified DL capabilities covering the full range of image, video, text, and speech under the banner of the Microsoft Cognitive Services. In January they introduced their fully automated platform, Microsoft Custom Vision Services (https://www.customvision.ai/).
The platform is limited to image classifiers and promises to allow users to create robust CNN transfer models based on only a few images capitalizing on MS’s huge existing library of large, complex, multi-image classifiers.
Using the platform is extremely simple. You drag and drop your images onto the platform and press go. You’ll need at least a pay-as-you-go Azure account and basic tech support runs $29/mo. It’s not clear how long the models take to train but since it’s transfer learning it should be quite fast and therefore, we’re guessing, inexpensive (but not free).
During project setup you’ll be asked to identify a general domain from which your image set will transfer learn and these currently are:
- General
- Food
- Landmarks
- Retail
- Adult
- General (compact)
- Landmarks (compact)
- Retail (compact)
While all these models will run from a restful API once trained, the last three categories (marked ‘compact’) can be exported to run off line on any iOS or Android edge device. Export is to the CoreML format for iOS 11 and to the TensorFlow format for Android. This should entice a variety of app developers who may not be data scientist to add instant image classification to their device.
You can bet MS will be rolling out more complex features as fast as possible.
Google Cloud AutoML
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=GbLQE2C181U[/responsive_video]
Also in January, Google announced its similar entry Cloud AutoML. The platform is in alpha and requires an invitation to participate.
Like Microsoft, the service utilizes transfer learning from Google’s own prebuilt complex CNN classifiers. They recommend at least 100 images per label for transfer learning.
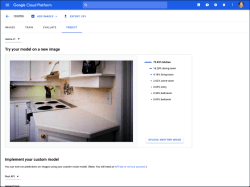
It’s not clear at this point what categories of images will be allowed at launch, but user screens show guidance for general, face, logo, landmarks, and perhaps others. From screen shots shared by Google it appears these models train in the range of about 20 minutes to a few hours.
In the data we were able to find, use appears to be via API. There’s no mention of export code for offline use. Early alpha users include Disney and Urban Outfitters.
Anticipating that many new users won’t have labeled data, Google offers access to its own human-labeling services for an additional fee.
Beyond transfer learning, all the majors including Google are pursuing automated ways of automating the optimal tuning of CNNs and RNNs. Handcrafted models are the norm today and are the reason so many often unsuccessful iterations are required.
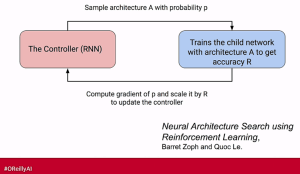
Google calls this next technology Learn2Learn. Currently they are experimenting with RNNs to optimize layers, layer types, nodes, connections, and the other hyperparameters. Since this is basically very high speed random search the compute resources can be extreme.
Next on the horizon is the use of evolutionary algorithms to do the same which are much more efficient in terms of time and compute. In a recent presentation, Google researchers showed good results from this approach but they were still taking 3 to 10 days to train just for the optimization.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=c3a4OilFeAM[/responsive_video]
OneClick.AI
OneClick.AI is an automated machine learning (AML) platform new in the market late in 2017 which includes both traditional algorithms and also deep learning algorithms.
OneClick.AI would be worth a look based on just its AML credentials which include blending, prep, feature engineering, and feature selection, followed by the traditional multi-models in parallel to identify a champion model.
However, what sets OneClick apart is that it includes both image and text DL algos with both transfer learning as well as fully automated hyperparameter tuning for de novo image or text deep learning models.
Unlike Google and Microsoft they are ready to deliver on both image and text. Beyond that, they blend DNNs with traditional algos in ensembles, and use DNNs for forecasting.
Forecasting is a little explored area of use for DNNs but it’s been shown to easily outperform other times series forecasters like ARIMA and ARIMAX.
For a platform with this complex offering of tools and techniques it maintains its claim to super easy one-click-data-in-model-out ease which I identify as the minimum requirement for Automated Machine Learning, but which also includes Automated Deep Learning.
The methods used for optimizing its deep learning models are proprietary, but Yuan Shen, Founder and CEO describes it as using AI to train AI, presumably a deep learning approach to optimization.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=yofjFQddwHE[/responsive_video]
Which is Better?
It’s much too early to expect much in the way of benchmarking but there is one example to offer, which comes from OneClick.AI.
In a hackathon earlier this year the group tested OneClick against Microsoft’s CustomVision (Google AutoML wasn’t available). Two image classification problems were tested. Tagging photos with:
Horses running or horses drinking water.

Detecting photos with nudity.

The horse tagging task was multi-label classification, and the nudity detection task was binary classification. For each task they used 20 images for training, and another 20 for testing.
- Horse tagging accuracy: 90% (OneClick.ai) vs. 75% (Microsoft Custom Vision)
- Nudity detection accuracy: 95% (OneClick.ai) vs. 50% (Microsoft Custom Vision)
This lacks statistical significance and uses only a very small sample in transfer learning. However the results look promising.
This is transfer learning. We’re very interested to see comparisons of the automated model optimization. OneClick’s is ready now. Google should follow shortly.
You may also be asking, where is Amazon in all of this? In our search we couldn’t find any reference to a planned AutoDL offering, but it can’t be far behind.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/automated-deep-learning-so-simple-anyone-can-do-it.
8 Best Deep Learning Certification, Course & Training [2018 UPDATED]
Posted on September 13th, 2018
Our team of global experts have compiled this list of the 8 Best Deep Learning Certification, Course, Training and Tutorial available online in 2018 to help you Learn Deep Learning. These are suitable for beginners, intermediate learners as well as experts.
Contents
- 1. Deep Learning Certification by Andrew Ng (Coursera)
- 2. Complete Guide to TensorFlow for Deep Learning with Python (Udemy)
- 3. Deep Learning A-Z™: Hands-On Artificial Neural Networks (Udemy)
- 4. Natural Language Processing with Deep Learning in Python
- 5. Modern Deep Learning Course in Python
- 6. Deep Learning Certification from Microsoft (edX)
- 7. Data Science: Deep Learning Tutorial in Python
- 8. Deep Learning Tutorial: Recurrent Neural Networks in Python
1. Deep Learning Certification by Andrew Ng (Coursera)
This is undoubtedly one of the most sought after deep learning certifications with Andrew Ng himself teaching the subject. The Co Founder of Global Learning Platform Coursera, Andrew has been the head of Google Brain and Baidu AI group in the past. Joining him are Teaching Assistants, Younes Bensouda Mourri from Mathematical & Computational Sciences at Stanford University and Kian Katanforoosh, Adjunct Lecturer at Stanford University. All in all, we have no doubt in proclaiming this as the Best Deep Learning Certification out there. In this certification course, you will learn about the foundations of Deep Learning, know how to build neural networks and understand all about machine learning projects. There will be real time case studies including sign language reading, music generation and natural language processing among others. Along with all the theory, you will be taught to implement these concepts in Python and TensorFlow.
Rating : 4.7 out of 5
Review : Course content is very good. Andrew Ng’s style of teaching is phenomenal. He has a knack for uncomplicating an otherwise complex subject matter. Highly recommended for anyone who is trying to understand the fundamentals of neural networks and deep learning.
2. Complete Guide to TensorFlow for Deep Learning with Python (Udemy)
Jose Marcial Portilla has an MS from Santa Clara University and has been teaching Data Science and programming for multiple years now. His training will help you learn how to use Google’s Deep Learning Framework – TensorFlow with Python. He will also teach you how you can use TensorFlow for Image Classification with Convolutional Neural Networks, how to do time series analysis with Recurrent Neural Networks and teach you to solve unsupervised learning problems with AutoEncoders. This training has been attended by close to 20,000 students and has got remarkable reviews and ratings.
Rating : 4.6 out of 5
Review – Excellent course. Portilla sets a pedagogical curve. Responsive Q&A, and reliable and regularly updated course materials are made available. Good foundation to a broad array of well-established and cutting-edge topics, and many useful external resources provided. – Jack Rasmus-Vorrath
3. Deep Learning A-Z™: Hands-On Artificial Neural Networks (Udemy)
A whooping 72,000 students have attended this training course on Deep Learning. Kirill Eremenko, Hadelin de Ponteves and the SuperDataScience Team, they are pros when it comes to matters of deep learning, data science and machine learning. Even basic high school level mathematics is enough for you to get started with this course and in the 23 hours of on demand video, the trainers will take you through all the necessary knowledge and information required by you to become proficient at deep learning. Specifically, you will learn about the intuition behind Artificial Neural Networks and Convolutional Networks, appying Artificial Neural Networks and Convolutional Networks in practice and much more around Recurrent Neural Networks, Self Organizing Maps and Boltzmann Machines. This is ideally one of the best deep learning course you will find out there.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=75qvwRXZjz4[/responsive_video]
Rating : 4.5 out of 5
Review – Very nice course! These two instructors know how to explain difficult concepts in simple terms. Kirill is an intuition god, and Hadelin explains every single line of code as you go through the examples. I feel comfortable enough to apply what I learned in this course in my own project. I definitely recommend this course to anyone who wants to understand the basic deep learning concepts and how they are implemented in the real world. – Raoul Noumbissi
4. Natural Language Processing with Deep Learning in Python
The trainer is a data scientist, big data engineer as well as a full stack software engineer. He has a masters degree in computer engineering with a specialization in machine learning and pattern recognition. With a CV like that, you should already feel assured with the quality of teaching for this deep learning program. This course will be like a complete guide on deriving and implementing GLoVe, word2vec and word embeddings. You will also be taught how to understand and implement recursive neural tensor networks for sentiment analysis. At 6 hours, this is a good crash course for those with not enough time on their hands.
Rating : 4.6 out of 5
Review – Instructor explains things vividly and with detail unlike some other instructors of machine learning. I recommend this course for serious data scientists. – Xiao Qiao
5. Modern Deep Learning Course in Python
In this deep learning training spanning 7.5 hours, with full lifetime access, you will learn to apply momentum to back propagation to train neural networks, apply adaptive learning rate procedures like AdaGrad, RMSprop, and Adam, understand the basic building blocks of Theano and then build a neural network in Theano. In addition to understanding TensorFlow, you will also write a neural network using Keras, PyTorch, CNTK and MXNet. In order to attend this program, you will have to be comfortable with Python, Numpy, and Matplotlib. You will have to install Theano and TensorFlow before or during the training.
Rating : 4.6 out of 5
Review – Clear and consistent. Goes over enough of the pre-requisites each course to refresh and remind the student of the foundations and then breaks new ground. Courses are updated often and stay current with the latest versions of the imports API’s. – Bill Hicks
6. Deep Learning Certification from Microsoft (edX)
In this deep learning certification by Microsoft, you will learn an intuitive approach to building complex models that help machines solve real problems. You will need to have basic programming skills, working knowledge of data science before signing up in order to make the most of this program. This course tries to enable engineers / data scientists and technology managers to eventually develop smart understanding of this technology. You will be taught how to use the Microsoft Cognitive Toolkit (CNTK) to tap into data sets through deep learning. Course is taught by Jonathan Sanito, Senior Content Developer at Microsoft, Sayan Pathak Principal ML Scientist and AI School Instructor, CNTK team and Roland Fernandez, Senior Researcher and AI School Instructor, Deep Learning Technology Center, Microsoft Research AI.
Rating : 4.4 out of 5
7. Data Science: Deep Learning Tutorial in Python
This program will serve as a guide for writing a neural network in Python and Numpy using Google’s TensorFlow. The trainer will teach you about how deep learning really works and how a neural network is built from basic building blocks. He will help you demystify various terms related to neural networks like “activation”, “backpropagation” and “feedforward”. There is a live project which is a part of the course to help you implement what you learn in real time.
Rating : 4.6 out of 5
[responsive_video type=’vimeo’]https://vimeo.com/162437052[/responsive_video]
Review – This is a very honest course taught by somebody who clearly understands the subject in great depth. As somebody who has been playing around with Keras, Scikit learn and Tensorflow for over a year, I have learned a huge amount through implementing models taught in this course just using Python. – Malcolm Mason
8. Deep Learning Tutorial: Recurrent Neural Networks in Python
Know all there is to know about the simple recurrent unit (Elman unit), GRU (gated recurrent unit), LSTM (long short-term memory unit) and also figure out how to write various recurrent networks in Theano in this course around recurrent neural networks in Python. To take up this program, you should know about backpropagation, understand Calculus and Linear Algebra. 10,000+ students have attended this course with great reviews and high ratings.
Rating : 4.6 out of 5
Review – This is the best intro to RNN that I have seen so far, much better than Udacity version in the Deep Learning Nanodegree. I really like the emphasis on the math: although it is not deep but it is clear enough so one get some mathematical intuitions on the working of the Recurrent unit. – Jean-Marc Beaujour
So that was our take on the Best Deep Learning courses, tutorials, certifications and training, specially for 2018. Do check out Best Machine Learning Online Course to dive deep into the domain and also Blockchain Training along with Best Python Certification. Since all these courses can be attended online, you have the benefit of carrying on learning from just about anywhere on the planet. We wish you all the best in your career! Team Digital Defynd.
Content retrieved from: https://digitaldefynd.com/deep-learning-courses-training-tutorial-certifications/.
How Deep Learning Will Change Customer Experience
Posted on September 11th, 2018
 Posted by Ronald van Loon on May 7, 2018 at 11:00pm
Posted by Ronald van Loon on May 7, 2018 at 11:00pmDeep learning is a sub-category within machine learning and artificial intelligence. It is inspired by and based on the model of the human brain to create artificial neural networks for machines. Deep learning will allow machines and devices to function in some ways as humans do.
Dr. Rodrigo Agundez of GoDataDriven is co-author of this article and very enthusiastic about the improvements that deep learning can offer. He’s been involved in the data science and analysis field for some time, and is already working on implementing models for practical applications.
Rodrigo notes that the new generation of users wants to interact with devices and appliances in a human-like manner. Take the example of Apple’s Siri, which allows for voice command and voice recognition. Communicating with Siri is similar to interacting with a human.
The user interface for Siri seems simple enough. However, the A.I. algorithms that are designed on the back-end are quite complex.
Designing this kind of interaction with a machine was not possible a few years ago. System designers now have access to complex deep learning algorithms that makes it possible to integrate such behavior into machines.
Importance of Deep Learning
Artificial Intelligence will never truly come of age without giving machines the powerful capabilities of deep learning.
The idea of designing deep learning models can be difficult to grasp for many people. This is because understanding human concepts comes naturally to us. But giving the same ability to machines is a very complex process of design.
One way to do it is by structuring data in a way that makes it easier to process for machines. Take the word “fat” for instance. If we say to a friend, “This burger has too much fat,” they would understand what we mean and the word would have a negative connotation here. But if we told a friend that “I would love to get fat from this meal any day,” the word would mean something entirely different.
Creating machines that are capable of understanding minute differences in words embedded in a context may seem like a very small thing, but requires a very large set of data and complex algorithms to execute.
Difference from Traditional Machine Learning
One way to differentiate between traditional machine learning and deep learning is through the use of features. These are the characteristics of the data that help us differentiate and identify one entity from another.
To understand features better, take the example of a normal bank transaction. Features of the transaction help us identify the timing of the transaction, the value transferred, names of the parties to the transaction, and other important information.
In a traditional machine learning model, features have to be designed by humans. In a deep learning model, features are identified by the A.I. itself.
We can take another example of differences between a cat and a dog. If we showed a person a cat and a dog and asked them to point to the cat, they would immediately identify it. However, if the same person was asked to identify the exact features that differentiate the two, they would have a problem. Both creatures have four legs, a body, a tail, and a head. They appear very similar in terms of features. Humans can distinguish one from the other in an instant. Yet, they would have trouble identifying the features that differentiate any pair of a cat and a dog.
This is a problem that data scientists and A.I. developers hope to solve with deep learning. Features can be found even in unstructured data with the help of deep learning algorithms.
Benefit from Deep Learning for the Customer Experience
Rodrigo states that deep learning models are superior at certain A.I. characteristics than any traditional machine learning models, as the models has shown its effectiveness. This can be traced back to 2012 where in a known online image recognition challenge, a deep learning algorithm proved to be twice as effective as any other algorithm before.
If an A.I. model reaches an accuracy of 50%, the device would not be very practical for use. Take the example of automobiles. A person would not trust getting in a car where brakes work 50% of the time.
However, if the accuracy of an A.I. system reaches values around 95%, it would be much more reliable and robust for practical use. Rodrigo believes that this level of accuracy for human-like tasks can only be achieved with deep learning algorithms.
Deep learning can be applied to speech recognition to improve customer experience. Speech recognition technology has been around for quite some time, but it didn’t cross the accuracy boundary to become a marketable product until the introduction of deep learning models.
Home automation systems and devices work through voice command. This is an area where deep learning can significantly improve customer experience.
Royal FloraHolland Case
Royal FloraHolland is the biggest horticulture marketplace and knowledge center in the world. An essential part of their process is having the correct photographs of the flower or plants uploaded by suppliers. These photos need to have a plant, some images require a ruler to be visible or a tray to be present.
The task of sorting through all these photographs manually and quickly is basically impossible, therefore it was decided to implement A.I. for the process.
GoDataDriven designed a system with deep learning algorithms to automate the checking of the images. The system can accurately identify and sort pictures taken from different angles and devices.
The system removed the need for manual human review and completely automated the process for the company.
University Medical Centrum Groningen (UMCG)
Deep learning algorithms were developed for UMCG with collaboration from GoDataDriven, Google and Siemens. This involved the use of MRI data in a 4D format (volume + time). Using deep learning models, the team calculated the heart ventricles volumes evolution over time.
One of the project goals is to assist in the decision making regarding pace makers and treatments. For example, it could take the heart cycle and volumes into consideration for prognosis and heart failure.
More than 400 images were taken per patient for different hearth depths across time. The team at GoDataDriven and Siemens developed multiple models, including binary and multi-class segmentation.
The model based on the U-Net deep learning architecture takes the MRI scan as input and outputs the corresponding volumes.
Traditionally, the process is done manually by looking at the scans and interpreting the results through hand-drawn diagrams.
Future of Deep Learning
Deep learning provides a way for companies to develop life-long learning modules. When more complex and richer algorithms are developed on top of pre-existing ones, companies will be able to achieve incremental growth.
Rodrigo believes that deep learning has a bright future because of its open source community and accessible platforms. Major corporations such as Apple which had built their systems on secrecy are finally coming around to the open-source model.
The main reason they are switching now is because they find deep learning talent acquisition more difficult in comparison with open source companies, such as Google’s Deep Mind for example. A company could have developed the most amazing and efficient deep learning system but if they don’t publish their research and share the knowledge online, talented data scientists and deep learning practitioners will not apply to this companies.
Currently deep learning teams like Google Brain, Google Deep Mind and companies like Facebook and Baidu find it much easier to hire talented deep learning practitioners. They continuously publish research and open source the related implementations, such that the deep learning is reminded that these companies are at the cutting edge of these technologies.
Since the shift is towards open source and global adaptation of this technology, deep learning is likely to do well in the future and impact vast sectors of in our society. T
About the Authors
Dr. Rodrigo Agundez

Rodrigo Agundez is Data Scientist and Deep Learning specialist for GoDataDriven. Rodrigo has worked as a consultant in numerous artificial intelligence projects and has given multiply deep learning trainings and workshops inside and outside The Netherlands. If you would like to know more about the exciting world of deep learning don’t hesitate to contact him via LinkedIn or Twitter.
Ronald van Loon
Ronald van Loon is Director at Adversitement, and an Advisory Board Member and Big Data & Analytics course advisor for Simplilearn. He contributes his expertise towards the rapid growth of Simplilearn’s popular Big Data & Analytics category.
If you would like to read more from Ronald van Loon on the possibilities of Big Data and the Internet of Things (IoT), please click “Follow” and connect on LinkedIn, Twitter, and YouTube.
Content retrieved from: https://www.datasciencecentral.com/profiles/blogs/how-deep-learning-will-change-customer-experience.
10 Best Data Science Certification, Course & Tutorial [2018 UPDATED]
Posted on September 7th, 2018
Our team of global experts have done extensive research to come up with this list of 10 Best Data Science Certifications, Degree, Course, Tutorial and Training available Online for 2018. These include free and paid learning resources and are relevant for beginners, intermediate learners as well as experts.
Contents
- 1. Data Science Course A-Z™: Real-Life Data Science (Udemy)
- 2. Python for Data Science and Machine Learning Course
- 3. Machine Learning Certification by Stanford University (Coursera)
- 4. Microsoft Professional Program in Data Science (edX)
- 6. Tableau 10 A-Z: Hands-On Tableau Training For Data Science!
- 7. Applied Data Science with Python Certification (University of Michigan)
- 8. Data Science Certification from John Hopkins University (Coursera)
- 9. Master of Computer Science in Data Science Degree Online (Illinois)
- 10. Data Science, Deep Learning, & Machine Learning with Python
- 11. Data Science: Deep Learning Tutorial in Python
- 12. Data Science Tutorial with R
1. Data Science Course A-Z™: Real-Life Data Science (Udemy)
Kirill Eremenko is a Data Science management consultant who helps businesses drive strategy, revamp customer experience and revolutionize existing operational processes. He has created 36 online courses so far and has taught over 400,000 students! At an average rating of 4.5 from 96,000 students you can be rest assured that he is one of the best tutors in the business. In this course he will teach you Data Science step by step through real Analytics examples including training you on Data Mining, Modeling, Tableau Visualization and more. Specifically you will learn about cleaning and preparing your data, performing basic visualization, modelling your data using tools such as SQL, SSIS, Tableau and Gretl. This is one of the Best Data Science tutorial you will find online and you will receive a certificate on completion.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=-hFBAC0D5tw[/responsive_video]
Rating : 4.5 out of 5
Review : It has been a great learning curve. I understood most things Kirill taught ( the question is do I remember them? hahaha!) Jokes apart, I honestly think he did a very good job at explaning all concepts particularly the tough mathematical/statistical contents. Well done! Kirill. I will be rewatching some of the videos again to refresh my memory. Overall it’s great value for money! Thanks Kirill for sharing your knowledge.
2. Python for Data Science and Machine Learning Course
This comprehensive course by Jose Portilla, a BS and MS in Engineering from Santa Clara University will help you understand how to use Python to analyze data, create beautiful visualizations and use powerful machine learning algorithms. Learn all about NumPy, Seaborn , Matplotlib, Pandas, Scikit-Learn, Machine Learning, Plotly, Tensorflow and much more in this 21.5 hour long tutorial which has already been attended by over 100,000 students globally. With high ratings and wonderful recommendations, this is a must attend program if you are looking to master the subject.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=bwtXJKg7OTY[/responsive_video]
Rating : 4.6 out of 5
Review : The best instructor i have ever seen and the Question and Answer forum has an immediate response. i love his teachings. Thank you sir. But i would like to suggest in MNIST lecture. i watched thrice, but i couldnt understand those 3 lectures, please update those lectures. but at the end, contriblearn made me satisfied. i was very confused about tensorflow. but in the end, i completely understood. hope you continue your lecture series. i want to learn more courses from you. – Chennakeshav Rao K
3. Machine Learning Certification by Stanford University (Coursera)
Andrew Ng, former head of Google Brain and Baidu AI Group has created this course along with other professors from Stanford University. It is one of the most sought after courses and certifications around machine learning available online. You will learn about Supervised learning, Unsupervised learning among other key areas and the course includes multiple case studies and applications to help you learn how to apply algorithms to build smart robots. This is one of the best data science certification you can opt for.
Rating : 4.9 out of 5
Review : This course is arguably the best place to start for anyone who wants to learn machine learning. I’ve tried other approaches before, like diving head first into neural networks without a clue about other simpler algorithms like linear and logistic regression and just got confused despite having no trouble with the mathematics. This course however made everything crystal clear. And I have yet to see an instructor as good as Andrew Ng. His enthusiasm was a great motivator.
4. Microsoft Professional Program in Data Science (edX)
This professional program by Microsoft consists of 9 courses in addition to a project and will take about 16 – 32 hours per course. It is a 10 course program and you can also choose individual courses if you want. You will learn about using Microsoft Excel to explore data, using Transact-SQL to query a relational database, creating data models using Excel or Power BI, applying statistical methods to data and using R or Python to explore and transform data Follow a data science methodology. The program is broken into 4 major units which further consist 10 courses. It is all followed by a project to help you apply all that you learn through the duration of this course.
Rating : 4.5 out of 5
5. Machine Learning Course A-Z™: Hands-On Python & R In Data Science
Kirill Eremenko and Hadelin de Ponteves along with their Super DataScience Team are masters when it comes to data science and they have together come up with this brilliant course to help you create Machine Learning Algorithms in Python and R. You don’t need any prior experience before signing up for this course and high school level mathematics understanding will be enough. It is a 40.5 hour long offering that will give you all knowledge required to excel in this field and has already been attended by more than 200,000 students worldwide.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=p317nw5Fj3o[/responsive_video]
Rating : 4.5 out of 5
Review : Kirill and Hadelin really took time to design the course such a way that understand the Concept very easily, even though if you don’t have any previous knowledge. On Top of it , specially having perfectly designed templates for various algorithms will make you feel very comfortable . Throughout the course if you follow the video , you are sure to get the concept of machine learning. And at the end of the course I’m quite confident to face any challenge in Machine learning world . – Prantik Bala
6. Tableau 10 A-Z: Hands-On Tableau Training For Data Science!
Kirill Eremenko, the Data Scientist & Forex Systems Expert has another wonderful course lined up and this time it is about Tableau 10. He will teach you data visualization through Tableau 10 and teach you all about customer purchase behavior and sales trends. He will empower you to prepare and present data easily.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=q03vxIt2BkM[/responsive_video]
Rating : 4.7 out of 5
Review : All of Kirill’s courses are awesome, and this one is no exception. I already knew how to use Python and R for data science, but this course got me very excited in Tableau! I would love to use Tableau for most data science visualizations from now on – possibly excepting machine learning visualizations, since Tableau cannot train machine learning models AFAIK (although it can forecast).
7. Applied Data Science with Python Certification (University of Michigan)
This is a 5 course program from the University of Michigan which will help you learn data science through the python programming language. You will need to have basic knowledge of Python and will be taught about popular python toolkits such as pandas, matplotlib, nltk and networkx among others to make sense of data. In particular, the 5 courses will cover Applied Plotting, Charting & Data Representation in Python, Applied Machine Learning in Python, Applied Text Mining in Python and Applied Social Network Analysis in Python. You will be taught by Christopher Brooks, Kevyn Collins-Thompson, Daniel Romero and V. G. Vinod Vydiswaran.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=lFpcZKBUiSY[/responsive_video]
Rating : 4.5 out of 5
Review : Great class! Right amount of challenging for someone with some Python (or scripting) background to cover some useful Pandas scenarios. Only critique is the coding challenges would be better if error logs were provided.
8. Data Science Certification from John Hopkins University (Coursera)
This certification course from John Hopkins will help you launch your Data Science career. It consists of a nine course introduction to data science, developed and taught by leading professors including Roger D. Peng, PhD Associate Professor, Biostatistics; Brian Caffo, PhD and Jeff Leek, PhD Associate Professor, Biostatistics. In this program, you will learn about R Programming, Getting and Cleaning Data, Exploratory Data Analysis, Reproducible Research and Statistical Inference among host of other areas. The training will be followed by a Capstone Project, where you will build a data product using real-world data. Our team of experts feels that this is one of the best Data Scientist certification you will find on the web.
Rating : 4.5 out of 5
Review : The Professor’s are just amazing in their knowledge. The slow bits of information and the way testing is done is so methodical and so well planned. If anybody says they are bored then I am sure they are bluffing, as I found out how enjoyable online learning can me. I am 40, working and a father of 2 children, time is scarce and this online way of learning with financial aid, I could not ask for anything more. Coursera is helping people like me find a hope of learning at their own pace, place and with their financial aid program helping poor people from developing countries like India see the light at the end of the tunnel.
9. Master of Computer Science in Data Science Degree Online (Illinois)
This Master of Computer Science in Data Science (MCS-DS) is an Online Degree from Illinois. You will be taught to build expertise data visualization, machine learning, data mining and cloud computing. It is offered in collaboration with the University’s Statistics Department and top-ranked iSchool. Multitude of entrepreneurs, educators, and technical geniuses have graduated from this school. This is one of the few Data Science Degree Courses available online.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=pJoYt7Yh4z0[/responsive_video]
Rating : 4.5 out of 5
10. Data Science, Deep Learning, & Machine Learning with Python
Frank Kane is an expert at all things data science and with this tutorial, he will teach you all about neural network, artificial intelligence and machine learning techniques. This comprehensive data science tutorial with over 80 lectures includes loads of Python code examples. Frank, with his previous experience at Amazon and IMDb will teach you all about what matters. Specifically, you will learn to make predictions using linear regression, polynomial regression, and multivariate regression; understand complex multi-level models; build a spam classifier and learn much more in 12 hours of on demand online lectures.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=PWExUJ_di2M[/responsive_video]
Rating : 4.5 out of 5
Review : Excellent explanations. Easy to follow. GREAT examples! This is a phenomenal class and Frank is an extraordinary instructor! I recommend this class / tutorial to all very interested!
11. Data Science: Deep Learning Tutorial in Python
This program will serve as a guide for writing a neural network in Python and Numpy using Google’s TensorFlow. The trainer will teach you about how deep learning really works and how a neural network is built from basic building blocks. He will help you demystify various terms related to neural networks like “activation”, “backpropagation” and “feedforward”. There is a live project which is a part of the course to help you implement what you learn in real time.
[responsive_video type=’vimeo’]https://vimeo.com/162437052[/responsive_video]
Rating : 4.6 out of 5
Review – Very nice course, it is well organized and explained. The exercises and examples are interesting and practical, maybe a bit too easy if an expert. The pace is good and everything covered thoroughly. Extra help lecture provided for troubleshooting.
12. Data Science Tutorial with R
With a BS and MS from Santa Clara University, Jose Marcial Portilla also comes with years of experience as a professional trainer for Data Science and programming. His client base over the years includes General Electric, Cigna, The New York Times, Credit Suisse among many others. In this data science tutorial, he will teach you how to use the R programming language for data science. Few of the topics that will be covered include programming with R, advanced R Features, using R to handle Excel Files, web scraping with R, connecting R to SQL, using ggplot2 for data visualizations and many other areas.
Rating : 4.6 out of 5
Review : Great course, amazing teacher. Although I have a background in software development and databases, I had never used R before or employed statistical methods. After taking this course, including the recommended reading and the exercises, I feel confident in being able to use R and the machine learning methods covered in the course.
Bonus Courses
13. Deep Learning Certification by deeplearning.ai
Learn how to build neural networks and lead successful machine learning projects in this 5 course specialization from deeplearning.ai . You will be taught about Python, Tensor Flow, RNNs, LSTM, Adam, Convolutional Networks and Xavier initialization among other aspects. The program is taught by Andrew Ng, Co-founder, Coursera & Adjunct Professor, Stanford University; Younes Bensouda Mourri, Mathematical & Computational Sciences, Stanford University and Kian Katanforoosh, Adjunct Lecturer at Stanford University, deeplearning.ai, Ecole Centrale Paris. This is one of the most sought after programs on Deep Learning available online.
[responsive_video type=’youtube’ hide_related=’1′ hide_logo=’0′ hide_controls=’0′ hide_title=’0′ hide_fullscreen=’0′ autoplay=’0′]https://www.youtube.com/watch?v=VLQHpvuwsV0[/responsive_video]
Rating : 4.9 out of 5
Review : Very useful course. Gives great insight on the hyper parameter tuning, regularisation and optimisation. One request I have is to provide a docker image which we can use to run the exercises locally. Sometimes I found it hard to build the environment where I can run the coursework. Some of the installations are clashing and it is not clear what versions of libraries are used in the coursework environment. It sometimes requires unnecessary effort.
14. Advanced Machine Learning Certification by Higher School of Economics
A total of 21 professors and researchers have come together to create this course; and this is undoubtedly one of the most comprehensive courses on data science and machine learning. This is an intermediate level course only relevant if you have basic knowledge around the subject. The course includes CERN scientists who will share their experiences of solving real-world problems using data science. This is a 7 course curriculum, and it will take you deep into the world of machine learning.
Rating : 4.8 out of 5
Review : Great course. Teaches you a lot of techniques and hands-on assignments. The course covers extensively on how to achieve a better score in Kaggle with tips and techniques. The real-world data science would be slightly different to this. But nevertheless, the content is refreshing along with the links, supplement materials associated
15. Excel to MySQL: Analytic Techniques for Business Certification from Duke University
Taught by Jana Schaich Borg and Professor Daniel Egger, this course from Duke University will help you formulate data questions, visualize datasets and inform strategic decisions. Learn how to use Excel, Tableau and MySQL to analyze data, build models and communicate your insights. It is all followed by a project where you will apply your skills to work on a real world business process.
Rating : 4.7 out of 5
Review : The course was very well organized. Instead of just teaching tableau the course covered aspects about how to approach a business problem, design ways to approach a problem, structured thinking and then went to solving those problems using tableau. Even after tableau was taught the instructor covered aspects of how to present it to the target audience and make an impact. Great work. Only suggestion will be to be up to date about the content as tableau comes up with upgrades but the course videos don’t include it.
16. Data Structures and Algorithms Certification from UC San Diego
UC San Diego and Higher School of Economics along with Computer Science Center and Yandex come together for this Data Structures and Algorithms Specialization spread across 6 courses. It is taught by a group of extremely proficient professors that include Daniel M Kane, Pavel Pevzner, Michael Levin, Neil Rhodes and Alexander S. Kulikov. There’s a good mix of theory and practice in this course where you will learn algorithmic techniques for solving various computational problems. This is one of the best Algorithms online course with the wealth of programming techniques it teaches you. The program also consists of two major projects : Big Networks and Genome Assembly.
Rating : 4.6 out of 5
Review : Thanks for the course. Content is good and videos are very well done. Only problem is that the assignment problems were gruelling and unfortunately it is hard to get one-to-one contact for help if you get stuck
Content retrieved from: https://digitaldefynd.com/best-data-science-certification-course-tutorial/.



